
Technology
Lambda Integration with MSK and KrakenD


API Gateways can be a simple way to expose asynchronous communication without revealing too many details about it but, is not always an easy task to implement. In this post, I explore a way to expose Kafka topics in a well-known API Gateway (KrakenD) while circumventing multiple limitations.
Balancing Asynchronous Complexity
In the world of software engineering, finding the right balance between complexity and abstraction is crucial. Over-abstracting can lead to complex systems, while too little abstraction results in code resembling a plate of “spaghetti alla bolognese”.
As engineers, we often use asynchronous communication to decouple systems, although this approach can introduce unexpected coupling, especially when relying on a single provider. Within asynchronous communication, we have three main options: Queues, Topics, and Streams, each with unique features and use cases. These distinctions can lead to unintended coupling between components, requiring specific libraries or code to connect to different providers.
In a Domain-driven context, it’s not always necessary to hide the provider, but minimising ties between subdomains is essential. Ensuring provider-agnostic communication is key; subdomains shouldn’t need to know the details of each other’s infrastructure. Instead, the focus should be on using well-defined contracts for successful data exchange. One practical solution to this challenge is implementing an API Gateway, which exposes Queues, Topics, or Streams as simple HTTP endpoints. This approach simplifies communication, hides subdomain internals, and eliminates unwanted couplings. However, selecting the right API Gateway can be trickier than it seems, as not all gateways offer seamless integration with asynchronous providers.
Current Scenario
In lastminute.com, after conducting an in-depth analysis, we decided to embrace KrakenD as our API Gateway solution, Kafka as our primary asynchronous provider, and AWS as our cloud provider. Given our choice of AWS, we also selected the Fully Managed Apache Kafka Service or MSK.
While KrakenD does provide a native method for connecting with various pub/sub providers such as RabbitMQ, AWS SNS/SQS, and Kafka, it’s important to note that the native implementation lacks support for authentication. Additionally, it exclusively operates with plaintext endpoints. Moreover, KrakenD does not offer a way to publish messages with headers and keys. Fortunately, KrakenD provides a practical option for invoking AWS Lambdas, which offers a solution to this challenge.
Proposed Solution
While invoking AWS Lambdas out of the box is fairly straightforward, it does come with a significant limitation – it cannot forward headers. This adds some complexity since including headers and keys in Kafka messages is a common use case. So, how can we overcome this challenge? Fortunately, there’s another feature in KrakenD that can help: request manipulation with Lua Scripting. This approach allows us to utilize HTTP headers to pass message headers and keys if these attributes are needed.
As you can see, the proposed solution revolves around using an AWS Lambda function to publish messages to the desired topic. However, a new challenge arises. Each topic uses a specific Protobuf schema to define the message contract, which is registered in the AWS Glue Schema Registry. Creating a separate Lambda function for each topic would be impractical to manage. Fortunately, there’s a solution – the Lambda can query the registry to retrieve the required schema. This means we can have one Lambda function that can be reused for any topic.
In summary, our proposed solution involves creating an endpoint in KrakenD. This endpoint will take the actual message contract as the request payload and accept custom optional HTTP headers to transmit the message headers and key. It will then consolidate this data into a single payload, invoke the Lambda function, pass the payload, and subsequently, the Lambda function will interact with the AWS Glue Schema Registry. It retrieves the schema and converts the JSON payload into Protobuf before publishing the message to the Kafka topic.
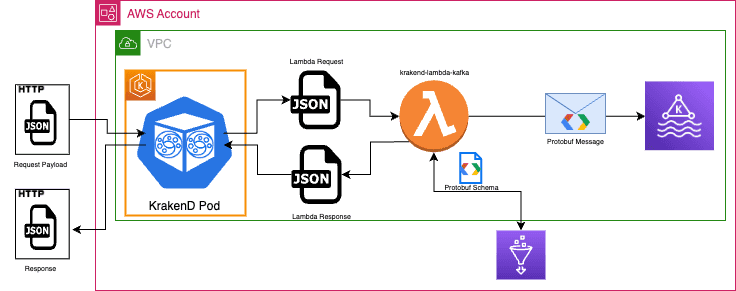
The AWS Lambda
The Lambda function will have a single responsibility: publishing messages to a Kafka topic. To achieve this, it will need to perform the following tasks:
- Receive the payload
- Retrieve the Protobuf schema from the registry.
- Transform the JSON message into Protobuf.
- Publish the message to the topic.
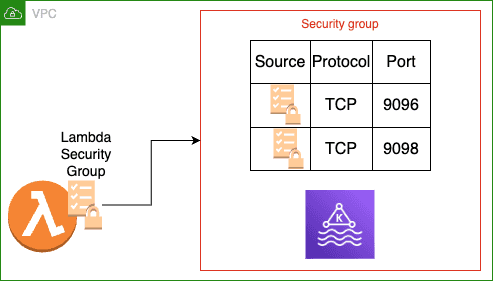
As shown in the previous image, the Lambda must be deployed within the same VPC as the MSK cluster. If not, the connection between the Lambda and the cluster becomes more complex because the Lambda will run in an AWS network outside of lastminute.com managed VPCs. This would require additional components, such as VPC Endpoints, leading to increased overall costs.
Since the Lambda will be deployed within a VPC, it will have a security group attached to it. It’s crucial to configure the security group attached to the Kafka cluster to allow the Lambda to access it.
Expected Input and output
This Lambda will require a specific JSON payload to publish messages to the Kafka cluster and consistently will return the same JSON response, indicating the status of the operation.
Input
The expected input should be a JSON object with the following structure
body: (Required)JSON Objectthat holds the message to be published on the Kafka cluster. This object must match the Protobuf schema defined for the topic.headers:(Optional)JSON Objectthat holds the headers to add to the message, TheJSON Objectcan only have pairs of key, values both in stings, and no actual object structure is allowed, for example:
"headers": {
"my_key":"myvalue",
"my_other_key":"42"
}topicName: (Required) String with the actual name of the topickey: (Optional) String that holds the key to add to the message
Full Example:
{
"body": {
"sample_message": "hello world"
},
"headers": {
"my_key": "myvalue",
"my_other_key": "42"
},
"topicName": "MyTopic",
"key": "messageKey"
}Output
Since this lambda will not be an HTTP service, it is not possible to return HTTP codes as a normal microservice would; however, this lambda will use the HTTP standard codes to indicate errors.
The output of this lambda is a JSON Object with the following structure:
statusCode:Stringthat indicates the status of the operation, the possible values are:200: The message was published.400: One expected input attribute is missing or the body does not match with the expected Protobuf schema.500: General error
message:StringMessage that gives more information about the status code, in the case ofstatusCodebeing200, you will always getok, in any other case, the message will explain a little why the lambda is returning that code.
Example:
{
"statusCode": "200",
"message": "ok"
}Lambda Code
The code of the lambda function is available at : https://github.com/lastminutedotcom/krakend-lambda-kafka
While AWS offers a range of languages for deploying Lambda functions, it’s important to note that in lastminute.com, Java is the primary language of choice. Therefore, the following code samples will be provided in Java, please be aware that this post is not intended to be a step-by-step tutorial on creating a Lambda function in AWS using Java. As a result, we’ll skip over certain details to keep it concise.
The proposed code has the following structure, the package structure will be omitted for simplicity:
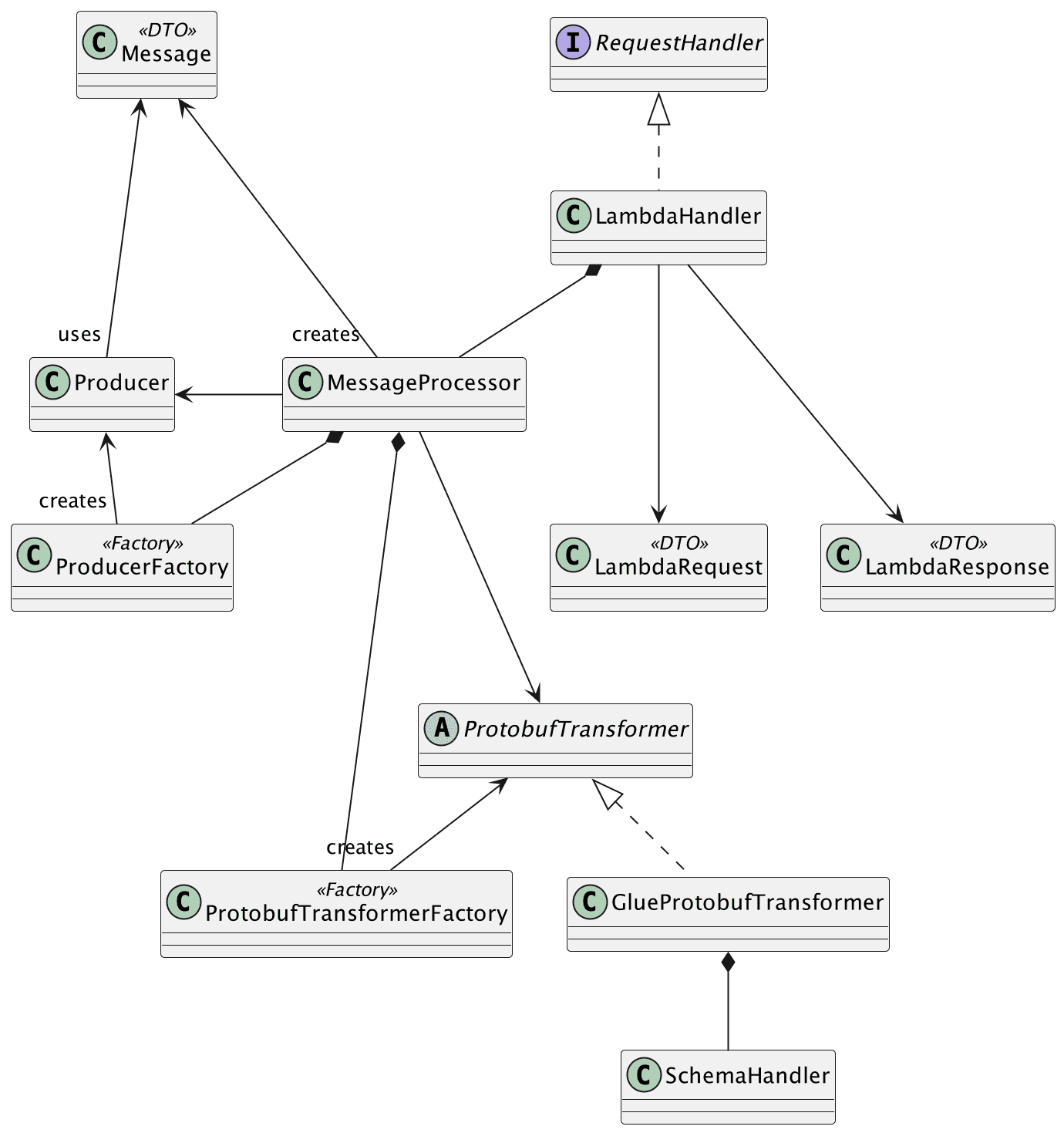
Let’s take a moment to discuss the classes and their roles, starting with the main class, LambdaHandler. This class is responsible for handling all aspects of Lambda invocation, including receiving input (request and context) and extracting the required environment variables for code execution. In Java, Lambda functions must implement the RequestHandler interface, which requires the code to override a method called handleRequest. In our example, it will look like this:
public Map<String,Object> handleRequest(LambdaRequest lambdaRequest, Context context) {
LambdaResponse response;
if(validateNotEmptyBody(lambdaRequest) && validateTopicNameIsPresent(lambdaRequest)){
response = processMessage(lambdaRequest);
}else{
response = LambdaResponse.builder().statusCode("400").message("body and topicName can not be empty or null").build();
}
LOGGER.info("Lambda response as map: {}",response.asMap());
return response.asMap();
}As can be seen this method receives an object called lambdaRequest, which serves as a Data Transfer Object (DTO) or _Plain Old \Java Object (POJO)_ defining the input data for this lambda function. AWS internally handles the serialization of the JSON payload into this object. Another object received is the Context. It offers various methods and properties that provide information about the invocation, function, and execution environment. In our example, this object will not be used.
The code within this method is rather straightforward. It validates the presence of certain required values in the payload. If all is in order, it processes the input; otherwise, it generates a 400 response. These responses are generated using another DTO (or POJO) known as LambdaResponse. In this particular case, we needed to return a Map instead of an object due to a serialization bug. For some reason, the serialized object couldn’t be read by the invoker, KrakenD in our case.
The next class is the MessageProcessor, responsible for processing received messages. This involves transforming the message into a Protobuf format and publishing it to the topic. These two tasks are delegated to separate classes, namely ProtobufTransformer and Producer. To simplify the creation of these objects, the MessageProcessor relies on two factory classes, responsible for generating new instances of these objects.
From here, things become quite straightforward. The ProtobufTransformer takes responsibility for acquiring the Protobuf schema definition and applying it to transform the payload. The operation of obtaining the schema is delegated to a concrete class; in this instance, the GlueProtobufTransformer handles all the necessary steps to connect to the AWS Glue Schema Registry and retrieve the schema. This final step is the responsibility of the SchemaHandler.
public class SchemaHandler {
private static final Logger LOGGER = LoggerFactory.getLogger(SchemaHandler.class);
private final GlueClient glueClient;
private final String registryName;
private final String schemaName;
private final SchemaId schemaId;
private final GetSchemaResponse schemaResponse;
public SchemaHandler(GlueClient glueClient, String registryName, String schemaName) {
this.glueClient = glueClient;
this.registryName = registryName;
this.schemaName = schemaName;
this.schemaId = this.getSchemaID();
this.schemaResponse = this.getSchemaResponse();
}
private SchemaId getSchemaID(){
return SchemaId.builder().registryName(this.registryName).schemaName(this.schemaName).build();
}
private GetSchemaResponse getSchemaResponse() {
try {
return this.glueClient.getSchema(
GetSchemaRequest.builder()
.schemaId(this.schemaId)
.build());
} catch (EntityNotFoundException nfe) {
LOGGER.error("Can not obtain the schema response, entity not found",nfe);
throw new RuntimeException("Error while trying to obtain the schema",nfe);
}
}
public String getSchemaDefinition(){
GetSchemaVersionResponse schemaVersionResponse = this.getGetSchemaVersionResponse(this.schemaResponse);
return schemaVersionResponse.schemaDefinition();
}
private GetSchemaVersionResponse getGetSchemaVersionResponse(GetSchemaResponse schemaResponse) {
try {
return this.glueClient.getSchemaVersion(getSchemaVersionRequest(schemaResponse));
} catch (EntityNotFoundException nfe) {
LOGGER.error("Can not obtain the schema version response, entity not found",nfe);
throw new RuntimeException("Error while trying to obtain the schema version",nfe);
}
}
private GetSchemaVersionRequest getSchemaVersionRequest(GetSchemaResponse schemaResponse){
return GetSchemaVersionRequest.builder()
.schemaId(this.schemaId)
.schemaVersionNumber(getSchemaVersionNumber(schemaResponse))
.build();
}
private static SchemaVersionNumber getSchemaVersionNumber(GetSchemaResponse schemaResponse) {
return SchemaVersionNumber.builder().versionNumber(schemaResponse.latestSchemaVersion()).build();
}
}The GlueClient object is an instance of software.amazon.awssdk.services.glue.GlueClient, thanks to that object it is possible to access the AWS Glue Registry and obtain the required schema, the configuration of that class is responsibility of GlueProtobufTransformer.
Now that the payload was transformed into Protobuf, is time to publish it into the topic, which course is responsibility of the class Producer, that class has a method like this one:
public void produceMessage(Message message){
ProducerRecord<Object,com.google.protobuf.Message> kafkaRecord= new ProducerRecord<>(message.getTopic(),message.getRecordKey(),message.getRecordMessage());
setupHeaders(kafkaRecord.headers(),message.getHeaders());
this.kafkaProducer.send(kafkaRecord);
this.kafkaProducer.flush();
this.kafkaProducer.close();
}It receives a Message object, this is just a simple DTO that holds the following information:
- Topic Name (
String) - Message Key (
String) - Message ( in
Protobufformat) - Message Headers (
List<Map<String, byte[]>>)
Then using a standard org.apache.kafka.clients.producer.KafkaProducer will publish the message, with the headers and key if present, into the topic
IAM Configuration
Like most services in AWS, the Lambda will utilize an IAM Role. This role must have policies attached to it that permit the following operations:
- Connecting to and publishing messages to the Kafka cluster.
- Accessing the schema registry.
To perform these operations, the following policies should be attached.
Please note that anything enclosed in braces ({}) and preceded by a dollar sign($) must be replaced with values that align with the current deployment.
Connection and publishing messages to the Kafka cluster
To perform this operation, you need to configure a policy responsible for enabling the connection to the cluster and granting write permissions to the topic.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"kafka-cluster:Connect",
"kafka-cluster:DescribeTopic",
"kafka-cluster:WriteData",
"kafka-cluster:WriteDataIdempotently"
],
"Effect": "Allow",
"Resource": [
"arn:aws:kafka:${region}:${account-id}:cluster/${cluster-name}/*",
"arn:aws:kafka:${region}:${account-id}:topic/${cluster-name}/*/${topic-name}"
]
}
]
}Accessing the schema registry
To be able to have access to AWS Glue and retrieve the schema it is required to attach a policy similar to the following one:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"glue:GetSchemaVersionsDiff",
"glue:GetSchema",
"glue:GetSchemaByDefinition"
],
"Effect": "Allow",
"Resource": [
"arn:aws:glue:${region:${account-id}:registry/${registry-name}",
"arn:aws:glue:${region1:${account-id}:schema/${registry-name}/*"
]
},
{
"Action": ["glue:GetSchemaVersion"],
"Effect": "Allow",
"Resource": ["*"]
}
]
}Configuring KrakenD
As mentioned earlier, we’ll leverage two KrakenD features to expose the topic as a simple HTTP endpoint: AWS Lambda invocations and Lua Scripting. But why and how are we going to use these features? Part of the ‘why’ was addressed earlier – the goal is to create an HTTP endpoint capable of receiving a payload to be published into the topic. To handle multiple topics effectively, we need to establish a convention for managing headers, keys, topic names, and payloads. The proposed convention is as follows:
- The method is recommended to be a POST
- The endpoint’s path should conclude with the exact name of the topic, respecting upper and lower-case characters. Anything defined before the topic name doesn’t matter, but it’s essential that the path ends with the topic name itself.
- The endpoint will only handle two headers:
message-headers: This header will contain the actual headers to attach to the message, the proposed format is key=value separated by commas, for example:message-headers:mykey=myvalue,otherkey=othervalue
message-key: This header is used to specify the key for the message and should accept only one value. For instance:message-key:mykey
Lua Transformation
Now, let’s dive into the ‘how’ part of the question. We’ll begin with Lua Transformation, Lua is a scripting language that allows us to generate the input expected by the Lambda. To achieve this, we’ll need to extract the HTTP headers, retrieve the topic name from the path, and obtain the payload. With all these elements in hand, we can construct the input necessary for invoking the Lambda. The following example will show how this can be done:
function lambda_request_transformation( req )
local reqBody = req:body();
local reqHeaders = req:headers("message-headers");
local messageKey = req:headers("message-key");
local path = req:path();
local jsonHeaders = generate_headers_json(reqHeaders);
local topicName = get_topicname_frompath(path)
local newRequestBody = generate_body_as_json(reqBody,jsonHeaders,topicName,messageKey)
req:body(newRequestBody);
end
function generate_headers_json(headers)
if not headers or headers == '' then headers = '{}' end
headersAsTable = {};
for key, value in string.gmatch(headers, "(%w+)=(%w+)") do
table.insert(headersAsTable, string.format("\"%s\":\"%s\"", key, value))
end
return "{" .. table.concat(headersAsTable, ",") .. "}";
end
function generate_body_as_json(body,headers,topic,messageKey)
bodyAsTable = {};
if not body or body == '' then body = '{}' end
table.insert(bodyAsTable, string.format("\"%s\":%s", "body", body));
table.insert(bodyAsTable, string.format("\"%s\":%s", "headers", headers));
table.insert(bodyAsTable, string.format("\"%s\":\"%s\"", "topicName", topic));
if not (not messageKey or messageKey == '') then
table.insert(bodyAsTable, string.format("\"%s\":\"%s\"", "key", messageKey));
end
return "{" .. table.concat(bodyAsTable, ",") .. "}";
end
function get_topicname_frompath(path)
index = string.find(path, "/[^/]*$")
return path:sub(index+1)
end
The response received by the Lambda also needs transformation because it’s not an HTTP call. As a result, the endpoint will always return a 200 status code. Inside the Lambda’s response, the actual code is present, so it’s necessary to inspect that code and return the corresponding HTTP status code. This task is handled by the following function:
function lambda_response_transformation( resp )
local responseData = resp:data();
local responseStatusCode = responseData:get("statusCode");
if not (responseStatusCode == nil) and not (responseStatusCode == '200') then
local responseMessage = responseData:get("message");
--TODO validate if message is not nil
custom_error(responseMessage,tonumber(responseStatusCode));
end
end
To keep things simple, it is better to define only one file where all two examples will be, in our case, we are going to put all that in a file named lambda_req_resp_transformation.lua.
Configuration File
KrakenD uses a JSON file called krakend.json for defining all the endpoints exposed in the API Gateway, in this post we will not enter into much detail on how that file is configured, but it follows this structure:
{
"$schema": "https://www.krakend.io/schema/v2.4/krakend.json",
"version": 3,
"endpoints": [],
"extra_config": {}
}We will focus on the ‘endpoints’ section. As can be seen, it’s an array, which means that it’s possible to add multiple endpoints. In this section, for each of the topics that need to be exposed as HTTP endpoints, you will be required to add the following, replacing all the values enclosed in braces ({}) and preceded by a dollar sign ($) :
{
"endpoint": "/${http-path}/${name-of-the-topic}",
"method": "POST",
"input_headers": ["message-headers", "message-key"],
"timeout": "50s",
"output_encoding": "json",
"backend": [
{
"host": ["ignore"],
"url_pattern": "/ignore",
"encoding": "json",
"extra_config": {
"backend/lambda": {
"function_name": "${actual-function-name}",
"region": "${aws-region}",
"max_retries": 1
}
}
}
],
"extra_config": {
"modifier/lua-proxy": {
"sources": ["lambda_req_resp_transformation.lua"],
"pre": "lambda_request_transformation( request.load() );",
"post": "lambda_response_transformation( response.load() );",
"live": false,
"allow_open_libs": true
}
}
}For example, if our topic is called MyTopic, will be exposed through the path /v1/event/ and will be handled by a lambda function deployed under the name my-lambda in the eu-central-1 region, the configuration will be something like:
{
"endpoint": "/v1/event/MyTopic",
"method": "POST",
"input_headers": ["message-headers", "message-key"],
"timeout": "50s",
"output_encoding": "json",
"backend": [
{
"host": ["ignore"],
"url_pattern": "/ignore",
"encoding": "json",
"extra_config": {
"backend/lambda": {
"function_name": "my-lambda",
"region": "eu-central-1",
"max_retries": 1
}
}
}
],
"extra_config": {
"modifier/lua-proxy": {
"sources": ["lambda_req_resp_transformation.lua"],
"pre": "lambda_request_transformation( request.load() );",
"post": "lambda_response_transformation( response.load() );",
"live": false,
"allow_open_libs": true
}
}
}AWS IAM Configuration
The last part in our puzzle is related to IAM, in the KrakenD documentation is explained in detail how to achieve this however in any case, will be required to attach the following policy to the IAM entity
Please note that anything enclosed in braces ({}) and preceded by a dollar sign($) must be replaced with values that align with your AWS Account.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["lambda:InvokeFunction"],
"Resource": "arn:aws:lambda:${region}:${account-id}:${function-name}"
}
]
}Cost Considerations
Cost is a crucial factor that should always be taken into account when deploying workloads on AWS. In this case, it’s no exception however, I want to emphasize that while cost considerations are important, this topic isn’t the primary focus of this post, as it could be a post of its own.
When implementing this approach, it’s essential to understand the primary cost factors. For instance, deploying your API Gateway on an existing Kubernetes cluster differs from deploying it on a new cluster, EC2 instances, ECS, or even App Runner. Each option comes with its own set of pros and cons, and the decision should be made on a case-by-case basis. The key takeaway here is that deploying anything in AWS incurs a cost, and in this case, deploying the API Gateway carries a cost.
The same applies to the Lambda functions. While you don’t need to worry about the deployment process, there is a cost associated with their use. AWS charges based on the number of requests and the time it takes to process those requests. This means that having one Lambda function per topic is not only complex to maintain but also expensive.
It’s worth mentioning that the Lambda presented here can be reused for multiple topics, which naturally raises the question of how many Lambdas are needed. The answer to this question depends on the specific use case, particularly the expected throughput for each topic.
It’s important to note that achieving the perfect balance will depend on each implementation. There’s no one-size-fits-all solution. However, it is possible to provide some guidelines regarding the number of Lambdas. For instance, considering that the pricing model is based on requests and time, it’s crucial to avoid cold starts, where the application needs to be redeployed, resulting in increased processing time. To optimize processing time, it’s recommended to group topics with low throughput or low usage together with topics expected to receive messages constantly. This approach minimizes the occurrence of cold starts.
At this point, we have identified two cost factors: the API Gateway deployment and the number of Lambda deployments. However, there are other factors to consider. For example, even though in this example, we have used the community version of KrakenD, you may need to purchase a license for the Enterprise version. This, of course, needs to be considered to make a more accurate estimate. Finally, there’s another hidden cost that can be quite tricky and easily overlooked: the network cost of AWS. It’s important to understand that cross-region and cross-availability zone traffic come with associated costs, and this must be taken into account when preparing a budget.
Wrapping It Up
This post intended to present a practical approach to hide Kafka topics behind an HTTP endpoint, reducing dependencies between components in a Domain-Driven environment. To achieve this, we opted for one of the simplest methods—a straightforward API Gateway.
In the practical example, which focuses on AWS, we chose KrakenD. To address the discovered limitations, we successfully employed a Lambda function capable of securely publishing messages to an MSK Cluster while also handling the transformation of messages from JSON to Protobuf.
It’s important to note that the Lambda function proposed here is not tied exclusively to the API Gateway. It can be reused to offer services and systems an option to publish messages to Kafka, especially when those systems lack a native library to do so.
Read next


Beyond Compliance: How We Built a Phishing-Aware Culture Across 1,700 Employees


Compliance checkboxes don't change behaviour. Here's how we used RIOT's AI-powered platform to run real phishing simulations, deliver contextual micro-training via Slack, and cut our vulnerability index by more than half across 1,700 employees. [...]






Written by lastminute.com folks, who live for the holidays. You should follow us on Twitter.

Want to express your love for travel and tech? Well, you could read another article, or you could just come and join us. We’re always looking for talent to help us enrich the lives of travellers - find your role here.
The postings on this site are authors' opinions and experiences and do not necessarily represent the postings, strategies or opinions of lastminute.com group.