
Technology
How living documentation and user stories acceptance tests can bring project documentation benefits?


In the software development community, it is a known fact that keeping documentation up to date according to the project requirements is something that needs team discipline. In different scenarios, it is possible to take advantage of a TDD/BDD approach and CI/CD pipeline artifacts to reach the goal of keeping software documentation according to the project deliverables.
Documentation in the Software Development Life Cycle
In the software development community, it is a known fact that keeping documentation up to date according to the project
requirements is something that needs team discipline.
Several issues (like project deadlines, corporate policies and processes, and other issues)
may impact to keep documentation quality aligned with source code.
A strategy to insert the project documentation in the SDLC (Software Development Life Cycle)
can help a team to keep it up to date with respect to the software evolution.
In different scenarios, it is possible to take advantage of a TDD/BDD approach and
artifacts generated through CI/CD pipelines to reach this goal.
Even being aware of the mentioned scenario in software projects, it is undeniable that projects need documentation to
register knowledge related to the business domain and also important aspects of the solution itself. When we come to the
reality of agile projects it is important to take into consideration that documentation might be the right fit for
project activities. However, it should not become something overwhelming and that will be the result of some effort that no one will
read.
BDD and effective software documentation
Within the context of lean and agile methodologies, there are established principles for crafting software documentation that is both efficient and impactful. The primary aim is to cultivate documentation that is easily updatable while also serving as a valuable knowledge repository for project members. Furthermore, this documentation acts as a facilitator in bridging communication between the project team and stakeholders.
The BDD (Behavior-Driven Development) is a software development process that emerged from TDD (Test-Driven Development), which started in the early 2000s. The main objective was to approach testing and coding and minimize misunderstandings. It has evolved into both analysis and automated testing at the acceptance level. Together with DDD (Domain-Driven Design), it was a useful tool to straighten the communication between the tech teams and stakeholders, once it uses natural language to describe acceptance criteria and software requirements. The goal is to shorten feedback cycles and eliminate misunderstood or vague requirements using real-world examples.

In this process a useful tool is the Gherkin language. Here is the description of Gherkin according to one of the references used to write this article:
Gherkin is a business readable language which helps you to describe business behavior without going into details of implementation. It is a domain specific language for defining tests in Cucumber format for specifications. It uses plain language to describe use cases and allows users to remove logic details from behavior tests. The text in Gherkin language acts as documentation and skeleton of your automated tests.
Gherkin offers a powerful way to craft human-readable specifications, while also serving as input to test automation given, its structure and meaning to executable specifications. In summary, we can say that having a Gherkin written specification it is possible to link automated test steps to provide outputs for test results execution and also have software specification documentation based on the Gherkin input files.
It’s important to distinguish this approach from traditional single test reports. Instead, the focus here is on cultivating living documentation for the application. Unlike test reports, which are typically examples converted into executable specifications that developers must adhere to during the Test-Driven Development cycle, living documentation represents a dynamic, human-readable record of each verified feature. This living documentation remains current and relevant through continuous updates driven by an automated test suite, serving as the ultimate output of the development process.
Getting living documentation in the software delivery process
Each of the topics covered thus far has served to lay the groundwork for justifying the integration of living documentation into the software delivery workflow. This integration aligns seamlessly with the principles of automated software delivery, particularly within the realm of CI/CD methodologies. Once a project has an orchestrated delivery process, it is straightforward to take advantage of it to bring to the project automated documentation.
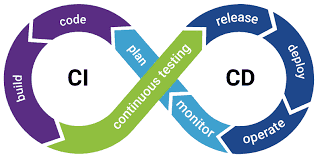
One of the important aspects of CI/CD is bringing visibility to the executed process. Part of this process is addressed to the tech team itself, but part of the visibility in the process means making it clear to the stakeholders. From the stakeholder’s perspective, the living documentation makes it possible to check the features validated and also the business rules covered in the application’s automated test process.
User Stories and event mapping
Since talking about living documentation is related to keeping software requirements and software implementation
integrated and aligned, it is necessary to link how it can be related to the source of an application’s requirements.
Agile projects will mainly register requirements
through User Stories. If we think of handling it
through a Domain Driven Design (DDD) and Event-Driven approach, they are mainly related
to Domain Events.
Thinking of a User Story as a description of a business need through a user perspective, the acceptance criteria written
in BDD fits as a matcher to validate if those business requirements are met.

When we think about Domain Events, the process is not so direct. So it is necessary to translate the dynamic vision of the Domain Events resulting from an Event Storming sessions to business requirements possible to be validated as an acceptance criteria.

In both cases, the main purpose is to create a relationship between the requirements artifacts and the software deliverables validation. In the practical example, it will become clearer how this relationship can be created.
Continuous testing to achieve living documentation
Once the team successfully aligns business requirements with software acceptance criteria,
the next hurdle is to find an efficient way of integrating tools to ensure seamless functionality.
Within the application lifecycle, this entails synchronizing test frameworks,
software specifications, implementation, artifact building, and CI/CD automated pipelines.
Considering that agile projects typically operate within a CI/CD framework,
they inherently possess the infrastructure to incorporate steps for generating living documentation.
The automated testing processes integral to application development serve as a solid foundation
for advancing in this direction.
This article presents an example that uses as main technologies:
- Gherkin: used to write the example specification
- Cucumber: used as the test framework for acceptance tests
- Serenity: used to tight it all together to bring BDD and living documentation
- GitHub actions: used to set up a CI/CD
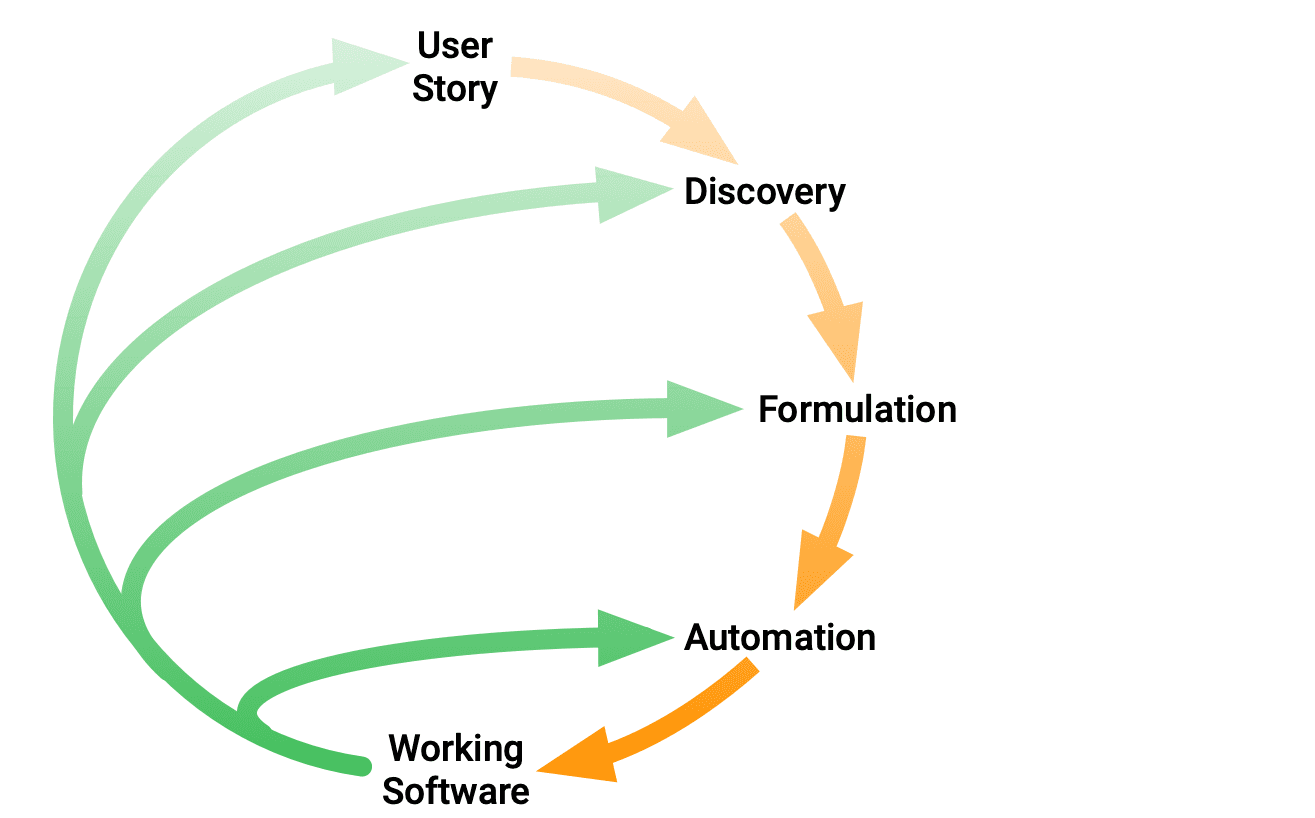
For a release delivery flow, it is possible to say that a set of user stories brings the discovery journey for a feature to the tech team. This will transform a business requirement into a feature that will be handled through an automated process which has as a final result working software.
Practical example
For demonstration purposes, I created this GitHub repository,
featuring a project implemented in Kotlin and utilizing Cucumber, Serenity, and Gradle.
This repository serves as a practical example of integrating a Behavior-Driven Development (BDD)
approach into the Software Development Life Cycle (SDLC) to facilitate business documentation generation.
Below, you can find a class diagram is provided to illustrate the example domain model of the project.
Within this domain, key business concepts include departments, courses, and students.
These concepts will serve as the primary epics for the project, guiding the classification of user stories.
Considering a proposal for developing the features in a possible BDD approach, it is possible to take into consideration a set of features done, a set of features as pending for the next software delivery cycles (to make it closer to an ongoing project following an Agile SDLC, simulating features done from a previous delivery, and pending features to be implemented in future sprints). According to the mentioned idea, this fictitious scenario is to help us to describe the living documentation approach. The repository has more details about it, but here it will be mentioned only the initial state of this possible scenario. For this domain, it is possible to consider the following set of use cases: a departments use case, a course use case, and a students use case.
Expected results over the documentation
The expected result is to have a separation of topics according to the project epics (Departments, Students, Courses). The project epics will be the starting point for creating the user stories. Each use case above has a set of scenarios that describe the business needs. Those business needs will be the input to create the user stories that will describe the application features. For each user story, there will be some acceptance criteria that will validate the business rule to be followed. It is possible to image that in the end we will have the stories contained in the image below.
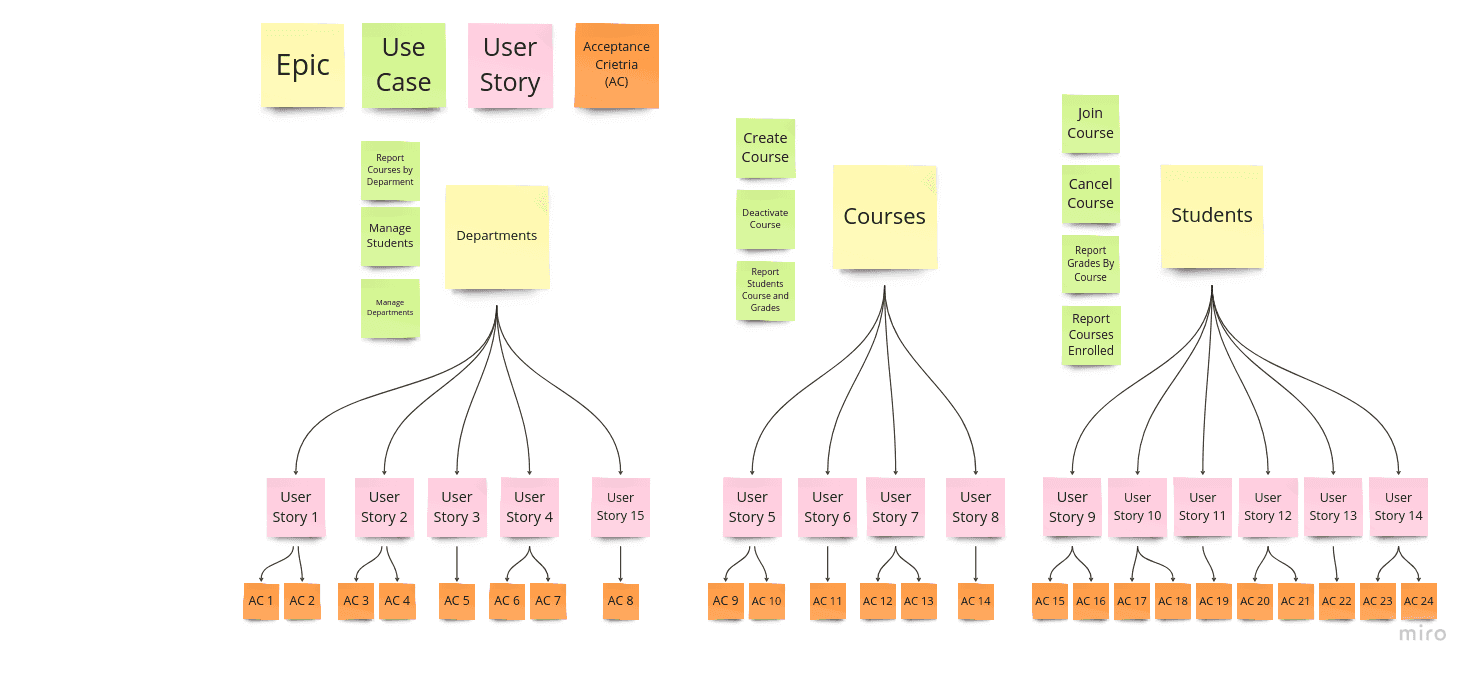
This user stories will be the base to create the files in the documentation for the BDD test cases and specifications. The user stories are grouped in epics, and each user story will have its acceptance criteria. The structure of the files will be explained better when presenting it in the source code project structure.
Project structure
Considering this initial project configuration, there is the test source code structure, the business specification, and the BDD files structure. For the test source code, there are 3 main components:
AcceptanceTestRunner: This class has the configuration for the Test Suite runner and the Cucumber configurations. I used a default configuration that can read the whole Spring context to do dependencies injection for the test context and the path for the feature files.CucumberSpringConfiguration: An empty stub just to enable the Cucumber context for a Spring Test class.<prefix>StepsDefinitionclasses: Those classes have the implementation for the Given/When/Then BDD validations related to the description written in the feature files. For this sample, they were grouped according to the Use Case definitions.
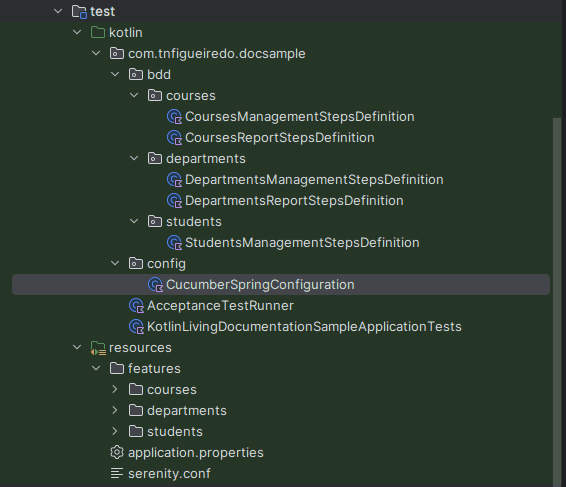
This project follows the recommended file structure mentioned in the Serenity official documentation.
The file structure was organized into a hierarchy for epics and features.
The feature files are used to describe the User Stories.
Epics are described through readme.md files, which bring the Epic business description.
Feature files contain User Story description and business rules, together with its acceptance criteria:
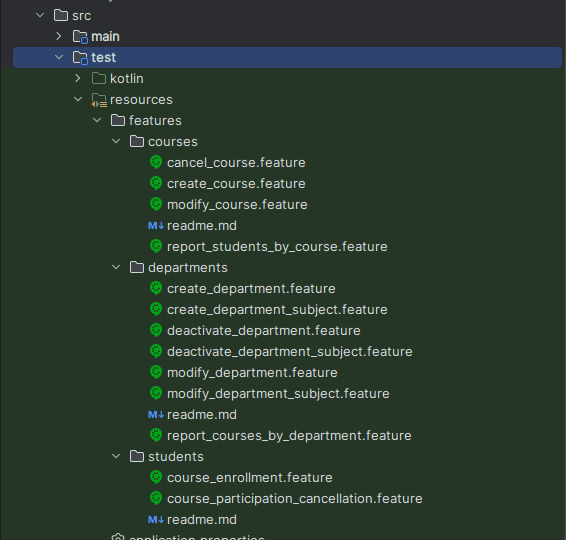
Once the files structure is defined, it is easier to understand how the Given/When/Then BDD definitions written in the
Gherkin files are related to the steps definition implementation.
In particular, the User Story feature files are related to the StepsDefinition BDD test implementation,
except for the Students Epic which has the implementation in a single class:
| Koltin Implementation | Feature File |
|---|---|
| CoursesManagementStepsDefinition.kt | cancel_course.feature |
| create_course.feature | |
| modify_course.feature | |
| CoursesReportStepsDefinition.kt | report_students_by_course.feature |
| CoursesManagementStepsDefinition.kt | create_department.feature |
| create_department_subject.feature | |
| deactivate_department.feature | |
| deactivate_department_subject.feature | |
| modify_department.feature | |
| modify_department_subject.feature | |
| DepartmentsReportStepsDefinition.kt | report_courses_by_department.feature |
| StudentsManagementStepsDefinition.kt | course_enrollment.feature |
| course_participation_cancellation.feature |
Here is an example for the mentioned files:
- Feature specification:
Feature: Create Courses
**As a** Departament Manager
**I want to** create a new course
**So that I can** have a course available in the department to offer to the students
Rule: A course can be created if there is no course for a subject between the initial and end date.
Scenario: Create a course successfully
Given A department administrator needs to manage course information
When it is informed the course information: "MyCourse2", "MyC2", "Programming", "2023-07-18", "2023-12-16"
Then a course is created successfully- Steps definition:
package com.tnfigueiredo.docsample.bdd.courses
import...
class CoursesManagementStepsDefinition {
private lateinit var creator: GeneralUser
@Given("A department administrator needs to manage course information")
fun givenDepartmentAdministratorNeedsManageCourseInformation(){
creator = GeneralUser(1, "dptoAdmin", UserProfile.DEPARTMENT_ADMINISTRATOR)
}
@When("it is informed the course information: {string}, {string}, {string}, {string}, {string}")
fun whenCourseInformationIsInformed(courseName: String, courseCode: String, area: String, startDate: String, endDate: String){
//TODO Implement
}
@Then("a course is created successfully")
fun thenCourseCreatedSuccessfully(){
//TODO Implement
}
}Those tests will have a common implementation already used to run validations like the integration and acceptance tests. The steps are called according to the description in the Gherkin files, and the description in the annotations needs to match the text described in the feature files.
Project build and report results
For this sample, it has not been created any special configuration for the report output folders. Considering so, the project
source code is generated in the project build folder, while the results for the Serenity reports are
generated in the target folder. The resulting report is generated in an HTML files format, into the folder structure
./target/site/serenity:
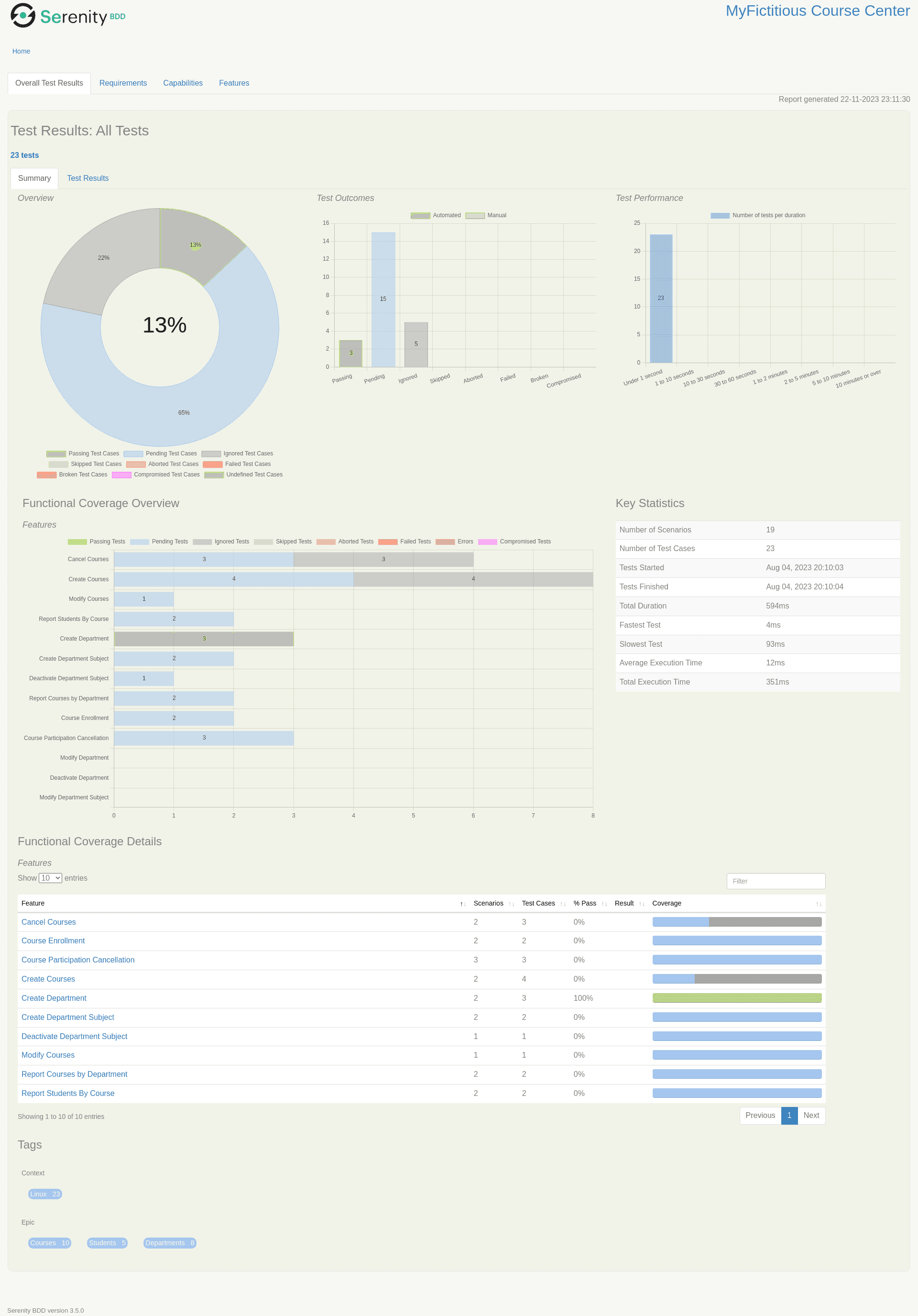
It is possible to open the resulting report in a browser through the index.html file generated in the Serenity reports
folder.
The first view is an overview of the project test cases grouped by a set of possible statuses.
This overview also presents test statistics and a classification.
In the case of this sample by Epic and Features:
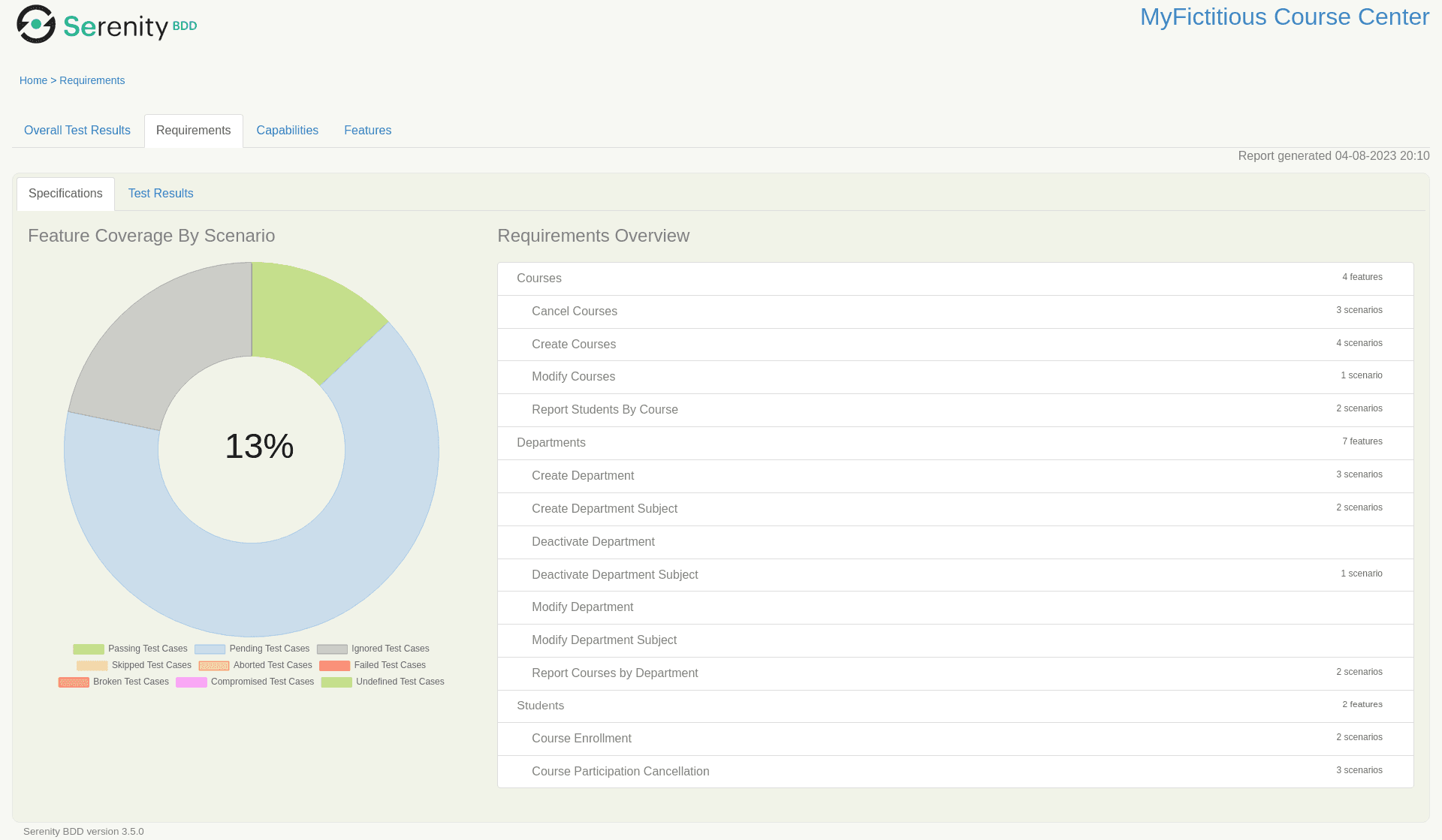
The “Requirements” tab presents an overview of the epics and the features classification, together with the test coverage scenario:
The “Capabilities” tab presents the Epics summary test cases:
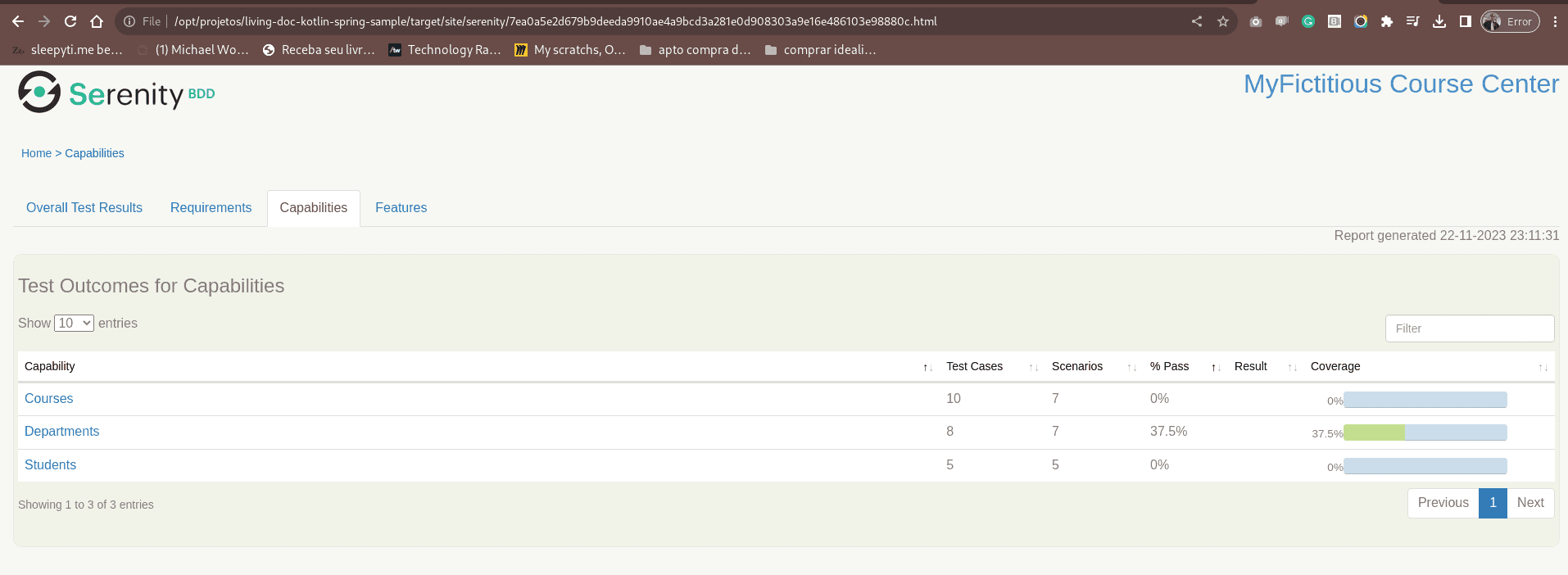
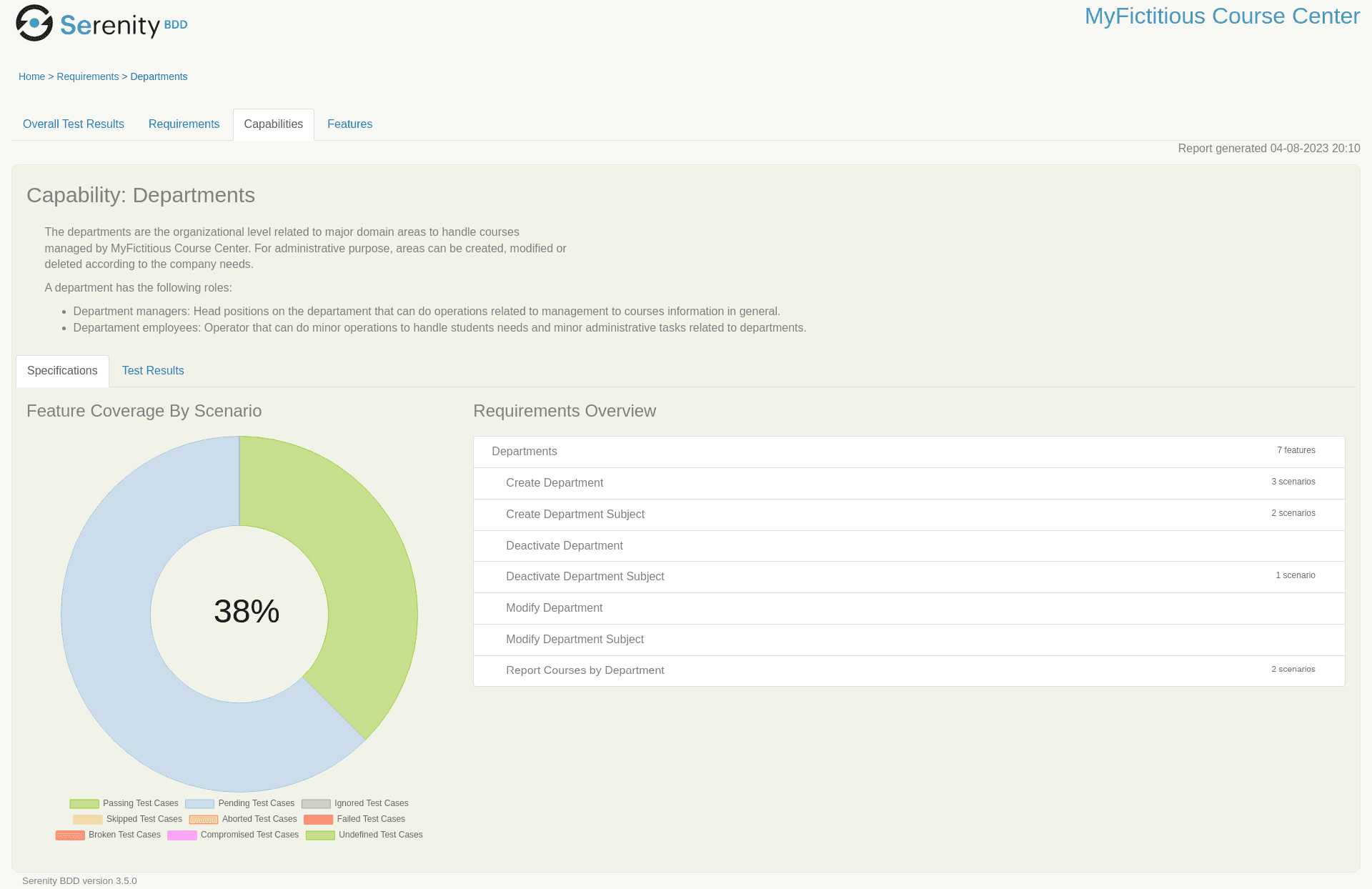
It is possible to check the readme.md epic file description when you click on a Capability:
The “Features” tab presents the Features summary test cases:
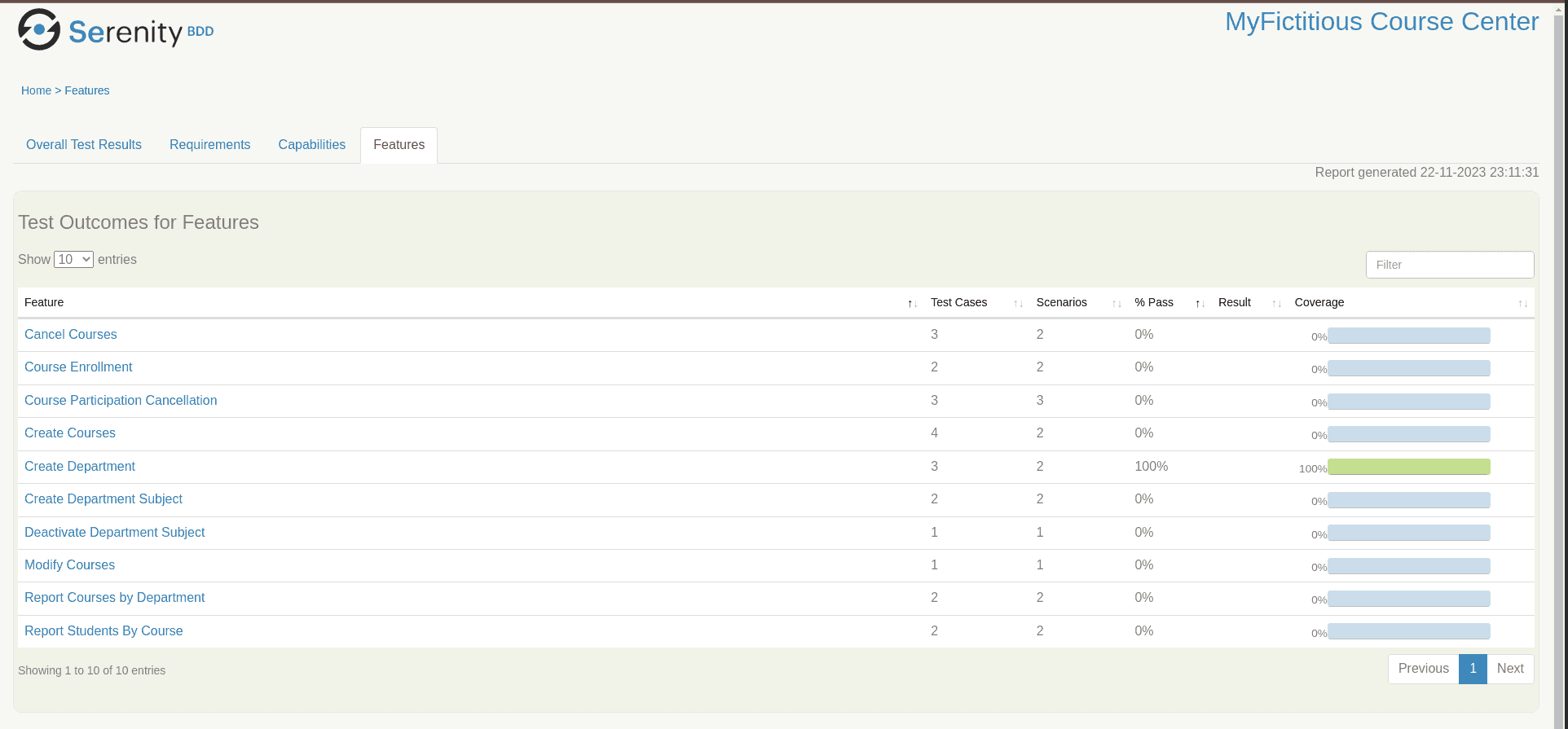
When accessing a specific feature, it is possible to check the feature description and the summary of its test cases:
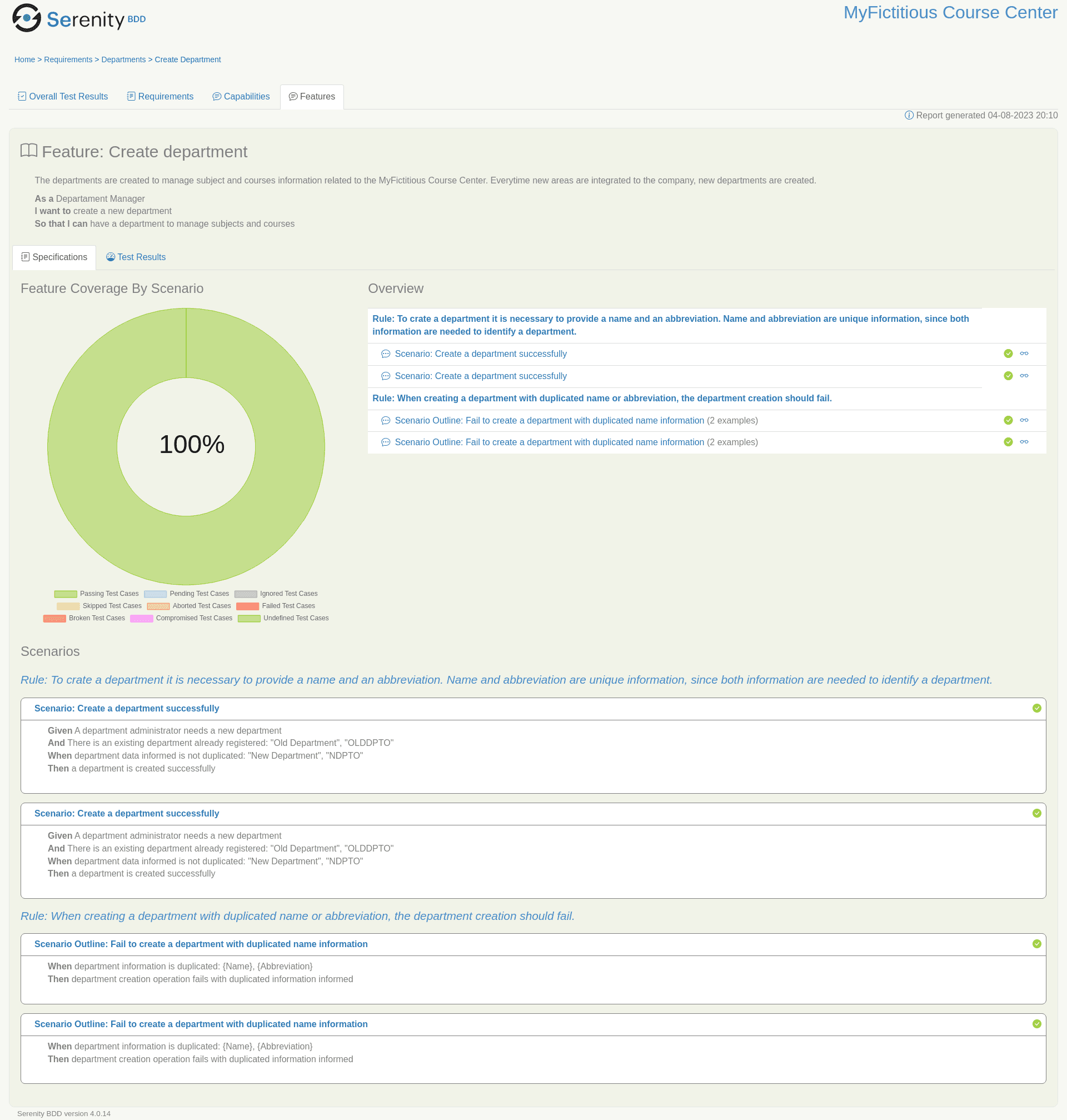
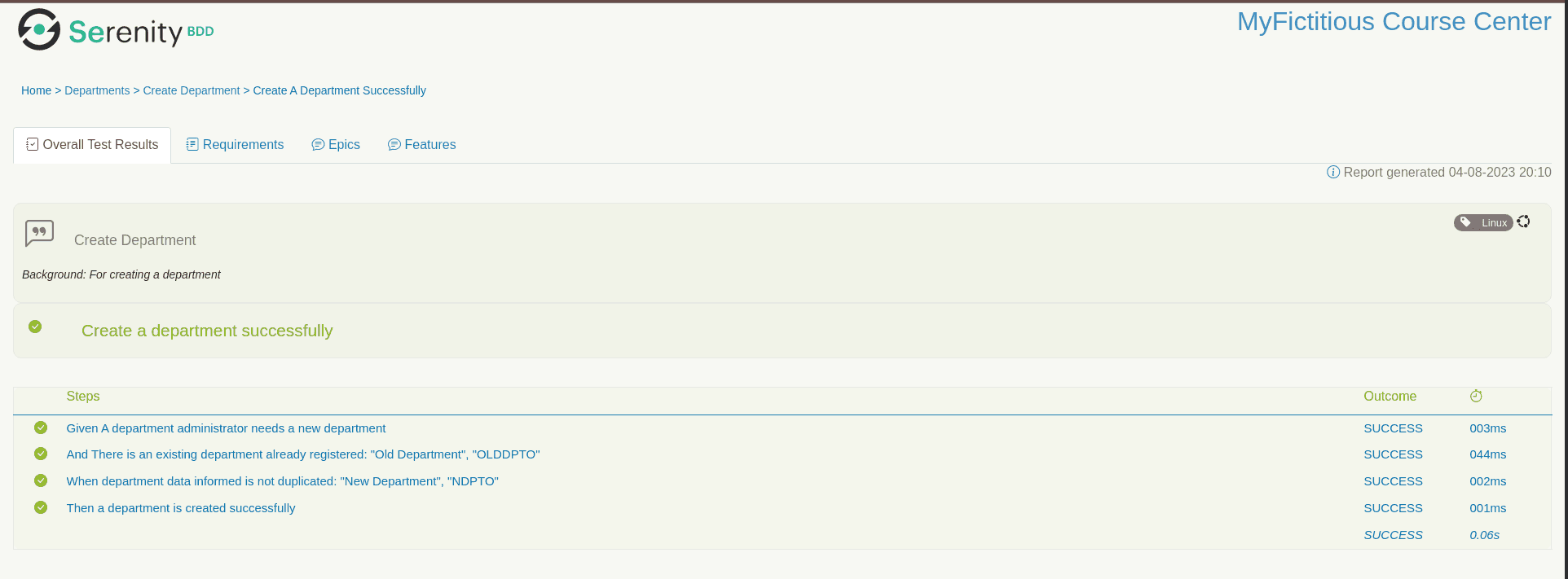
If it is accessed in a specific test case, it is possible to see its execution and description:
Final Considerations
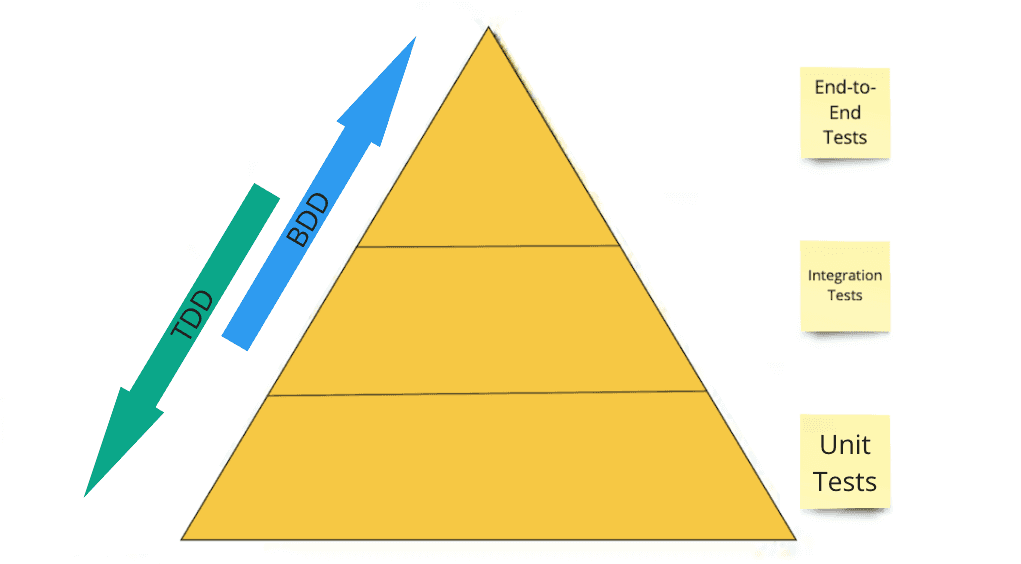
Taking into consideration the tests pyramid, it’s clear that the BDD tests will be very similar to acceptance tests and E2E (ent-to-end) tests. The focus is to validate business scenarios collected together with the stakeholders and other team members. This is also the reason why it improves communication with stakeholders. Since the validations are done in a business language, if the stakeholders are involved in the software process, they will be able to understand what was validated in the software releases.
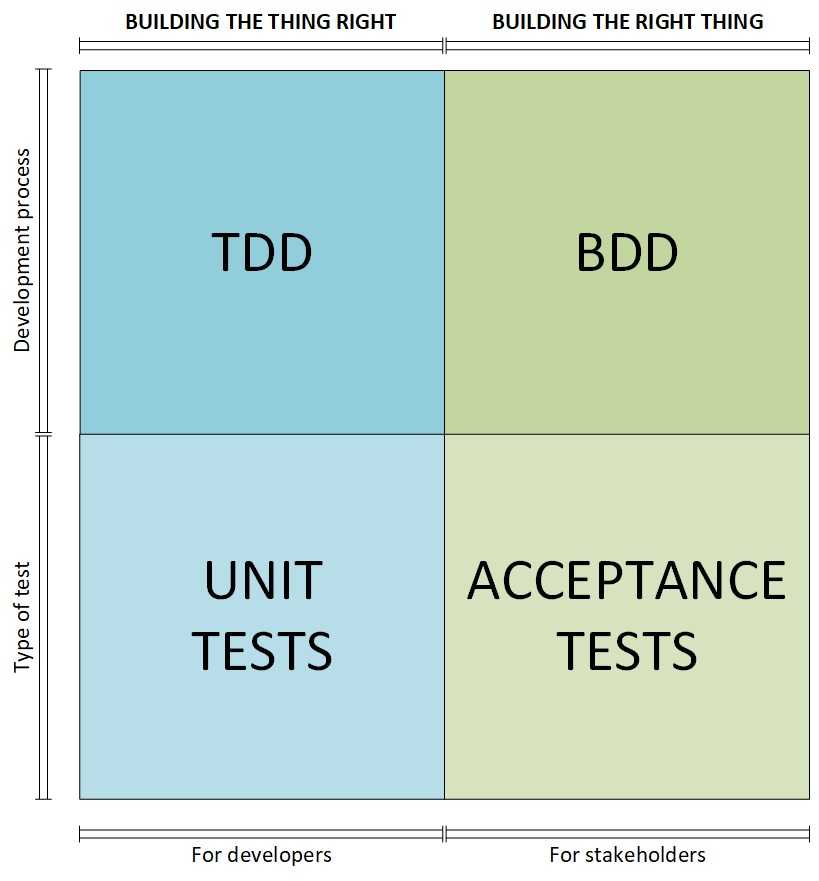
Taking into consideration the tech team perspective, it is possible to say that the BDD tests could also work like a regression test tool. Since they help to make sure that the business requirements remain behaving as expected through the delivery of the releases.
There are some project aspects that are important to be well planned due to impacts on the project and tests maintenance. But, even with some extra effort to have this layer of tests, it is possible to clearly achieve value to the project deliverables.
References
- Svetlana Novikova - The Holy Grail of “Always-Up-to-Date” Documentation
- Serenity official site - Living Documentation
- Scott Ambler - Core Practices for Agile/Lean Documentation
- Cucumber official site - History of BDD
- Thomas Hamilton - Gherkin Language: Format, Syntax & Gherkin Test in Cucumber
- Cucumber official site - Gherkin Reference
- Aurlane Pascal - Living Documentation vs. Test Reports: What’s the Difference?
- Cucumber official site - What is BDD?
- Mykhailo Poliarush - CI\CD and Automation Testing: What’s the Connection Between These Concepts
- Jan Stenberg - Behaviour-Driven Development: Value through Collaboration
- Liquibase official site - Visibility into the CI/CD Pipeline
- Mykhailo Poliarush - Writing BDD Test Cases in agile software development
Read next












Written by lastminute.com folks, who live for the holidays. You should follow us on Twitter.

Want to express your love for travel and tech? Well, you could read another article, or you could just come and join us. We’re always looking for talent to help us enrich the lives of travellers - find your role here.
The postings on this site are authors' opinions and experiences and do not necessarily represent the postings, strategies or opinions of lastminute.com group.