
Technology
Event Sourcing - A Light Introduction


Event Sourcing is not one of the most well known pattern in software engineering, but it has a lot of potential uses and areas of application. In this blog post I'd like to explain what is event sourcing, why it matters and why it naturally fits CQRS architectural pattern so nicely, together with an explanation of the various building blocks used.
Event Sourcing is not one of the most well known pattern in software engineering, but it has a lot of potential uses and areas of application. In this blog post I’d like to explain what is event sourcing, why it matters and why it naturally fits CQRS architectural pattern so nicely, together with an explanation of the various building blocks used by this pattern.
Part 1 - What is Event Sourcing and why it matters
Let’s start with an example:
In this example the company we work for is trying to build a full-fledged e-commerce site. One of the main components of this site will be the Shopping Cart.
Usually, when tasked to build a shopping cart, we would end up with a model close to the one depicted in the following figure.
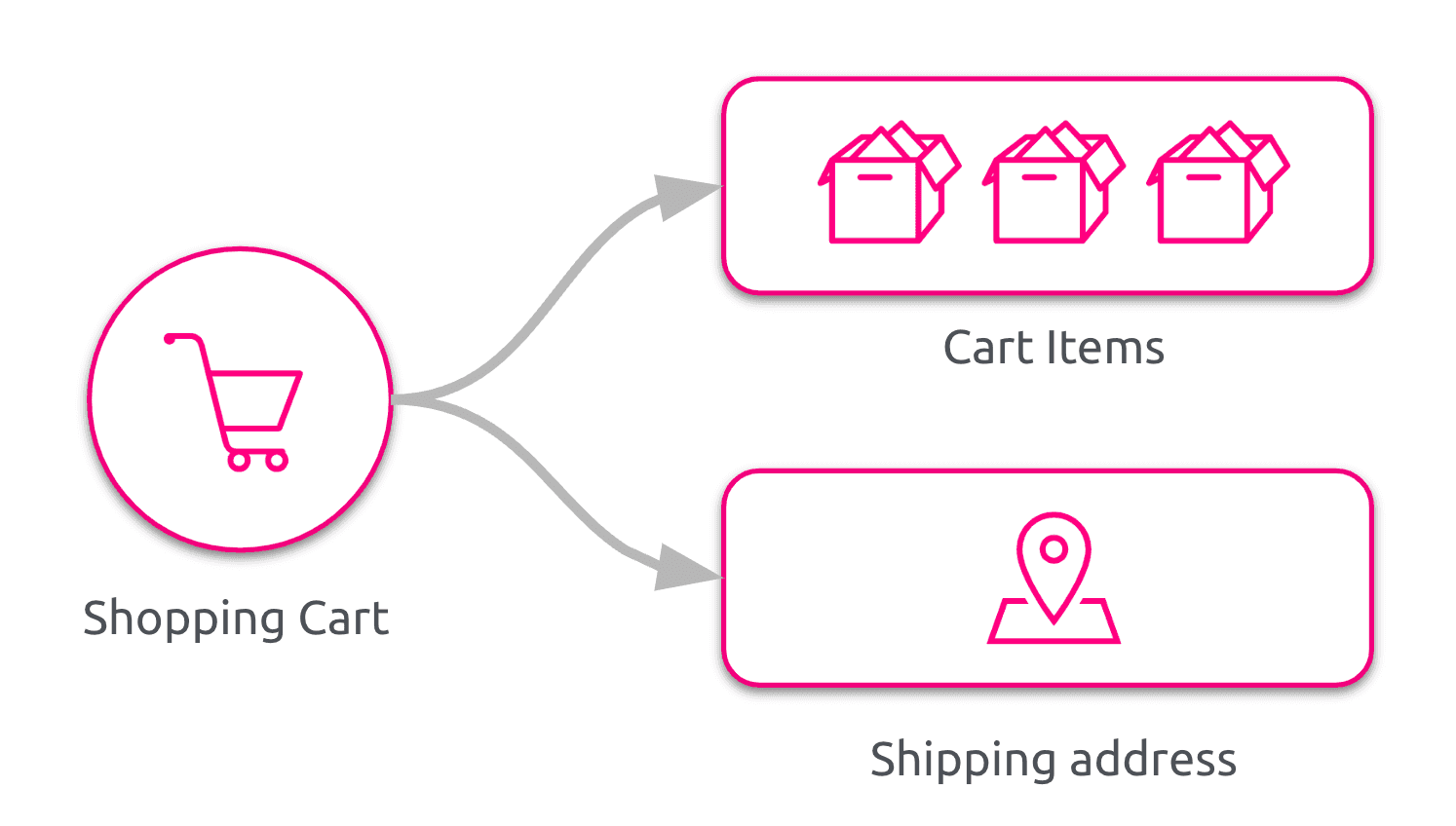
The first time a product is selected by our customer a Shopping Cart is created, and then the item is added to the Cart Items collection. Any subsequent product selected for purchase by our customer is simply added to the Cart Items collection. If our customer chooses to remove a product from our shopping cart the corresponding Cart Item is removed from the Cart Items collection. Chance is that such a model will be backed up by a traditional Relational Database. This is a Domain Model familiar to any developer and implemented in a lot of e-commerce platforms: for sure it will fulfill all the business needs in the near future!
One of the characteristic of this model is that it focuses on the final state of the shopping cart after any user interaction.
But the business always evolve to keep the peace with the market and business people always have new requirements to better support our users.
The product increment in this example is something like: “We want to know the product our users were interested in but they didn’t buy”. Our developer mind directly wanders exploring the concept of abandoned cart, but it’s not exactly what the business intended: the idea is to have a sort of report with all the products that all our users put into the cart, but were removed just before checkout.
We could tweak our model to add a collection containing Removed Cart Items like in figure.
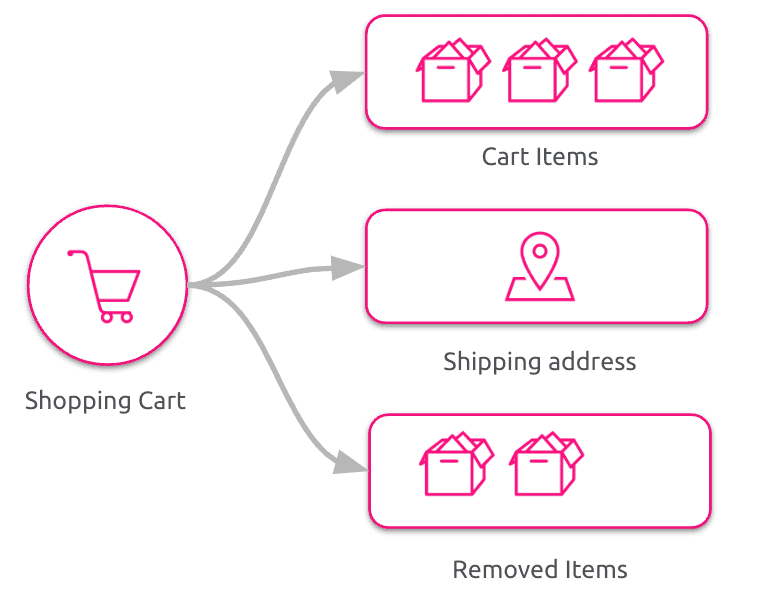
It would for sure fulfill our business need, but it feels a little clumsy: whenever a user add a product it is added to the Cart Items collection and whenever a user removes a product from the shopping cart it is removed from the Cart Items collection and added to the Removed Cart Items collection.
The problem we are facing with our traditional domain model, by focusing only on the final state of the shopping cart, is that we have lost all the information about “why” we ended up in that particular state.
A useful heuristic: if we can get in the same state with more than a sequence of actions, we are losing information.
Losing information we lose value. Unfortunately, we cannot know in advance how much valuable is a piece of information, so we need to find a way to preserve as much as we can.
What if, instead of focusing on the state of the application, we focus on facts that happened to lead our application to end up in that state? Back to our example: this means creating an event when our shopping cart is created, one event when a product is added to the cart, one event when a product is removed from the shopping cart, and so on.

What we have done is representing our model in terms of domain events, where each domain event represents a state change that happened in our model. A domain event is a full-fledged part of the domain model, a representation of something that happened in the domain relevant for the business. As a domain event represent something happened into the past, it’s by definition immutable. All the domain events are appended in strict chronological order to a stream of events. With this stream of events intuitively we can say that we have all the information we need to “fill” the traditional one. We are building a sort of audit log, which cannot deviate from what happened.
Using events to represent the state changes in our model we move the focus from the shape of the data and the current state of the system to the behaviour of the system itself, and we capture that behaviour in our model. Moreover, by the definition of domain events, we are sure to capture all the information relevant for the business. When we use events to persist our model state changes we are applying Event Sourcing.
Event Sourcing is the persistence mechanism where each state transition for a given entity is represented as a domain event that gets persisted to an event database.” (from: https://www.eventstore.com blog)”
Event Sourcing approach is not new: there are many applications and many domains that inherently work in this way. For example, Relational Databases are based on transaction logs, where everything happening in the system is saved before applying modification to the tables. Git works in this way, saving deltas for each modification in a file. Accounting, banking systems, financial markets are all domains where an event-sourcing-like approach comes naturally.
Given this our cart system could be represented both by its current state and the sequence of events leading to that state. Given the characteristics of the event stream we can assume that it is the source of truth and that we can derive a more traditional representation of our data from it. This representation is called Projection. We can derive from the event log more than one projection each one tied to a subset of use cases of our system. For example, in our cart system we could have a projection representing the current state of the system and one dedicated to the “unsold items” use case. The added benefit of this approach is that by storing events from the beginning of the system we don’t lose any information, and we can generate a report about unsold items with information starting from day 0.
Part 2 - Event Sourcing building blocks
How to support model changes
Let’s start with an example:
We need to support a withdrawal operation on a banking system Bank account - Withdrawal Operation A customer can withdraw money if the desired amount is within the current balance of their account
In our system the withdrawal request from our customer is represented by a command. To handle this command, we need to understand if it can actually be applied with success or if the invariants are violated and the requested operation is invalid. To check the invariants we need to rebuild the state of our aggregate, the banking account. Rebuilding the state of an aggregate from its event stream is called rehydration.
To rehydrate an aggregate from an event stream we need to reapply all the events generated in strict chronological order, starting from the oldest.
In this example we start from the event representing the initial balance of the account (State -> Account Balance = 20), then the two deposits of 100 (State -> Account Balance = 220) and finally we elaborate the withdrawal event of 150 (State -> Account Balance = 70).
Once the aggregate has been rehydrated we can finally check whether the command can be applied. In this case the account balance is greater than the withdraw amount so we can safely apply the command and mutate the aggregate state. The state of the aggregate is mutated by emitting an event which will be persisted on the event store. Once the event is persisted the aggregate state change is permanent and the transaction (on the aggregate itself) is closed. When we will need to rehydrate again this aggregate we will find in the event stream also the event tied to the last withdrawal and the state of the aggregate will be updated accordingly.
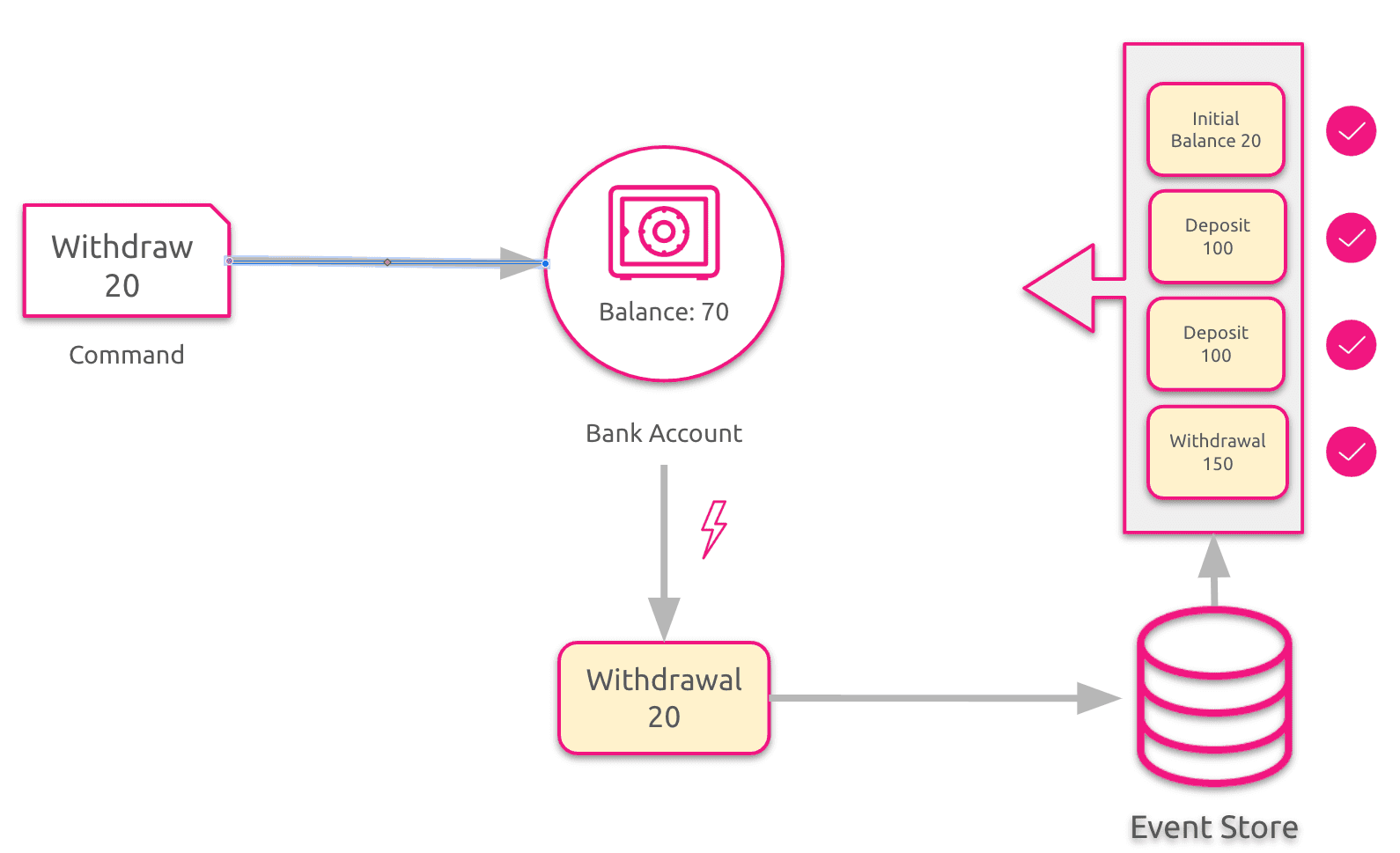
If the command violates the invariants of our model (i.e.: we ask for a withdrawal operation exceeding our account balance) then an error is raised and no event is emitted.
How to query application state
When using event sourcing we end up with a model specifically tuned for executing commands and not for querying application state. One way of accessing application state is rehydrating our aggregates in memory to offer the data we need, just like we are doing when we need to handle a command. This approach is suitable if we need data from a (really) limited number of aggregates, but it becomes rapidly inefficient as the system grows.
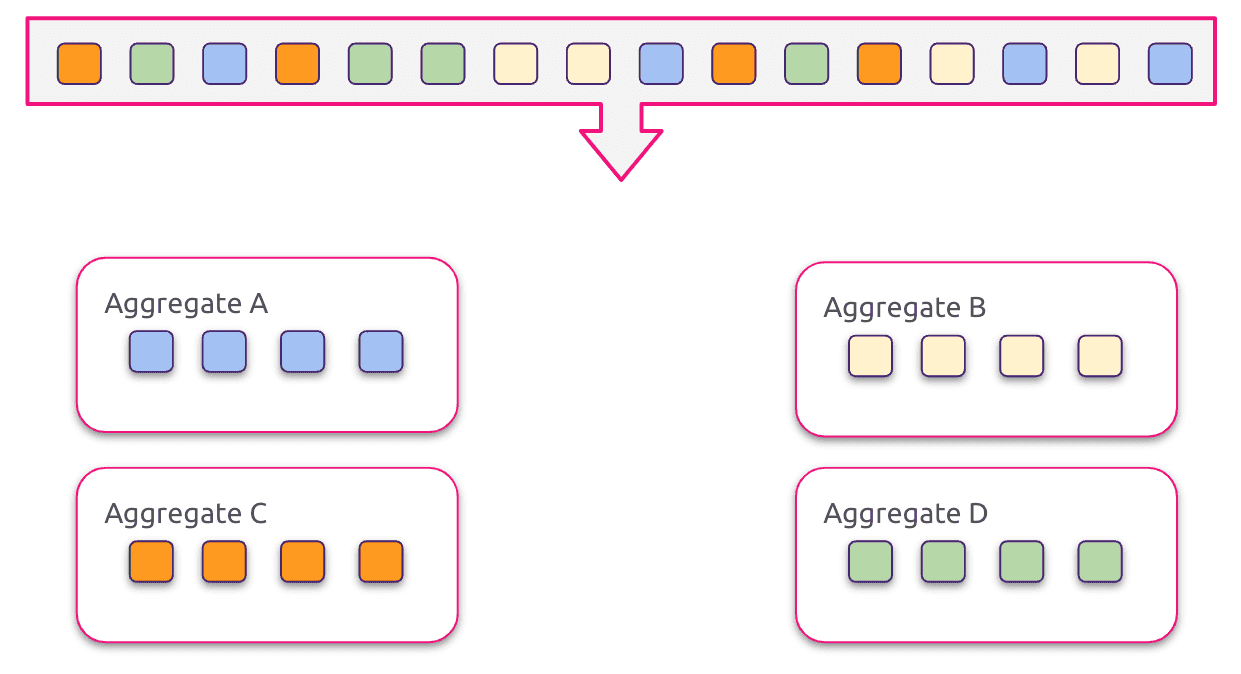
Another approach we can follow is to pre-calculate some data and update it as the events flow in our system, persisting it in a proper system. This materialised view of the event stream is called Projection. To create a projection the event stream is processed by a set of event handlers whose job is to persist the content of the event in a proper system. This approach doesn’t pose any kind of constraint neither on the number of projections nor on the technology used to support them: theoretically we should have a projection tailored to any use case of our system, backed by the best storage engine needed for the task at hand.
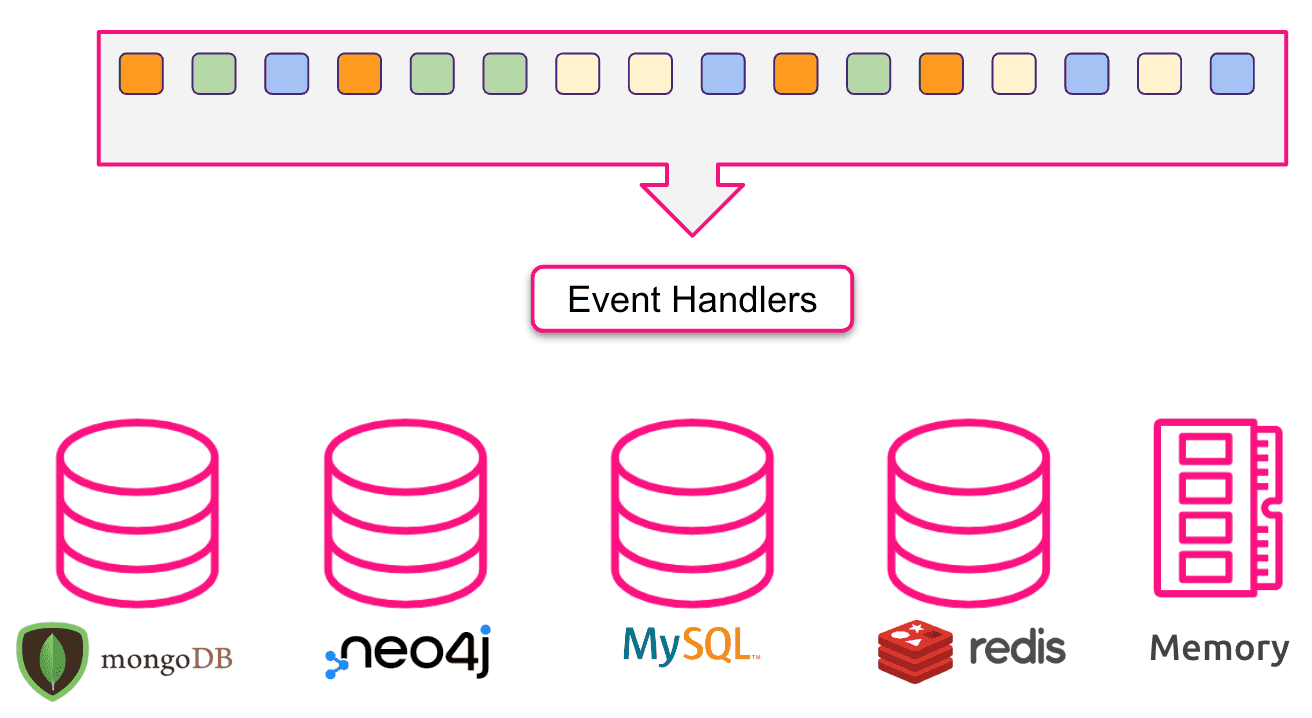
CQRS, the big picture
Now we have two separate sets of models, one tuned for executing commands (the write model) and one specifically tuned to access the application state (the read model). The write model and the read model communicate trough events. The state of projection needs to be updated and stored after write to an event store - it can happen in two ways:
- Synchronously - in the same transaction as the write to the event stream. This approach is usually very limited as it assumes the events are stored in the same database as the projection data. It also doesn’t scale easily, and has other operational problems (such as replays that can be impossible or hard to synchronise).
- Asynchronously - events are delivered to projections after they are written to the event store. Because the updates are asynchronous we will have to deal with eventual consistency of data stored by projections as well as with delivery guarantees. On the upside the projections are now decoupled from the main transactional write and can be scaled, replayed and monitored independently depending on the needs.

Wrap up
Benefits
- When developing an event sourced system our initial focus is on the behaviour of the application instead of the shape of the data on our storage;
- Auditability: by assuming that the event stream is the source of truth in our system we are creating an audit log which can neve be out of synch with the behaviour of our system;
- Improved debuggability: in case of any problem or bug in our system we can easily detect the defect by taking (part of) the event stream in a sandbox and reapplying the events one by one;
- Simplified persistence model: the event store basically boils down to a properly structured table, or to a dedicated system;
- Scalability: we are now able to scale in an independent way several part of the system;
- Right tool for the right job: we can choose the best technology for several part of the system with the only constraint of being able to produce/consume events.
Attention points
- Unfamiliarity: event sourcing is a technique not very widespread and there could be a costly ramp up;
- Asynchronicity: asynchronicity is not mandatory with an event sourced system but if we embrace CQRS we need to find a strategy to deal with it, if needed;
- External systems: external systems are a point of attention, especially if they are not event sourced! What happens if I rebuild a projection from scratch and the data on the external system changed in the meantime?
- Identifiers: if we need to expose data to external systems/users we need to find a strategy to generate identifiers;
- Event Schema: our system will evolve in time and we need to be prepared to deal with the evolution of the event schema;
- Overall complexity: an event sourced system is more complex than a traditional one: we need to be sure that this additional complexity is justified by our use cases.
Read next


From Months to Weeks: The Smart Way to Let AI Do a Migration




How we migrated 137 modules to a new dependency-injection pattern with AI, turning a quarter-long slog into a few focused weeks by teaching the AI instead of delegating to it, working in small supervised steps, and letting the method compound. [...]






Written by lastminute.com folks, who live for the holidays. You should follow us on Twitter.

Want to express your love for travel and tech? Well, you could read another article, or you could just come and join us. We’re always looking for talent to help us enrich the lives of travellers - find your role here.
The postings on this site are authors' opinions and experiences and do not necessarily represent the postings, strategies or opinions of lastminute.com group.