
Technology
Exploring the Monorepo


Monorepo has become quite popular in Javascript world, and yet not fully explored for JVM-based development. The lack of tools and practical examples slow down its adoption in everyday software projects. In this series of articles, we’ll try to uncover the full potential of a monorepo with Java and Maven.
Literally, monorepo means keeping the source code of many projects in a single repository.
Popular in environments like Node.js, monorepo remains nearly uncharted territory for Java developers.
Besides monorepo, polyrepo (also known as multirepo) is the most common topology for JVM-based development.
As opposed to monorepo, each project is stored in a separate repository.
There has been a lot of hype around this word for a few years, with big players like Google, researching and debating on how to shape their huge codebases. Features they seek to find in monorepo are enforcing standards and best practices, maintaining shared components, reducing cognitive load, and large-scale code refactoring. All things that in theory could be facilitated by code colocation.
When I came across the idea of monorepo, my first thought was “It works only with billions of lines of code or could it be useful in my daily work too?”
There is plenty of literature and documentation on the internet explaining what monorepo is, and comparing monorepo vs. polyrepo. This series of articles is not about that, and personally, I do not advocate for one or the other solution in general. Like always, there is no silver bullet — it mostly depends on the context.
Before we go further, let me tell you a bit about us.
Breaking the silos, breaking the monolith
Lastminute.com is a product-oriented company that fosters a culture of collaboration and innovation. Our management encourages knowledge sharing, and cross-pollination of ideas. In the tech department, there are plenty of internal initiatives that bring different teams to meet and work together, or help a developer enjoy the experience of working in other teams.
It hasn’t always been this way. Over the last 10 years, our company has grown fast and over a few countries. The growth forced a technological and cultural shift, from silos to synergy.
The open and collaborative philosophy has been profitable, both for technology and for the business strategy.
Generally, we organize the source code in one repository per project. The development of JVM-based applications is powered by tools like Maven, GitLab, Sonar, and Nexus to operate 400+ software projects. Our services are organized in a microservices ecosystem.
The source code is accessible to everyone in the company who wants to gain knowledge and collaborate to make it better.
Sometimes our teams share responsibilities over the same services and libraries, for example, when the process of delivering a new product feature spawns over multiple software components.
The service per team principle does not strictly apply to us
Time-to-market is very important, and this way helps to be flexible and deliver faster.
In my team, we have a history of converting monoliths to microservices. Migrating towards a microservices architecture necessarily required refactoring. The codebase had to be split.
Monorepo, why should I care?
In an ideal world, microservices shouldn’t depend on shared code or libraries — it’s known as an antipattern.
However, moving out of a monolith has been challenging. There were situations where a feature was in a piece of
code reused in two components, and we couldn’t simply reimplement the feature and remove the coupling at no cost.
In some cases, splitting the code of the monolith, we opted to reuse the source code instead of increasing the duplication with copy/paste. This practice usually implies creating a number of shared libraries … and coordinating versioning.
Versioning is a two-edged sword
Today, for every product feature we develop, possibly there are some libraries to manage and multiple services to release.
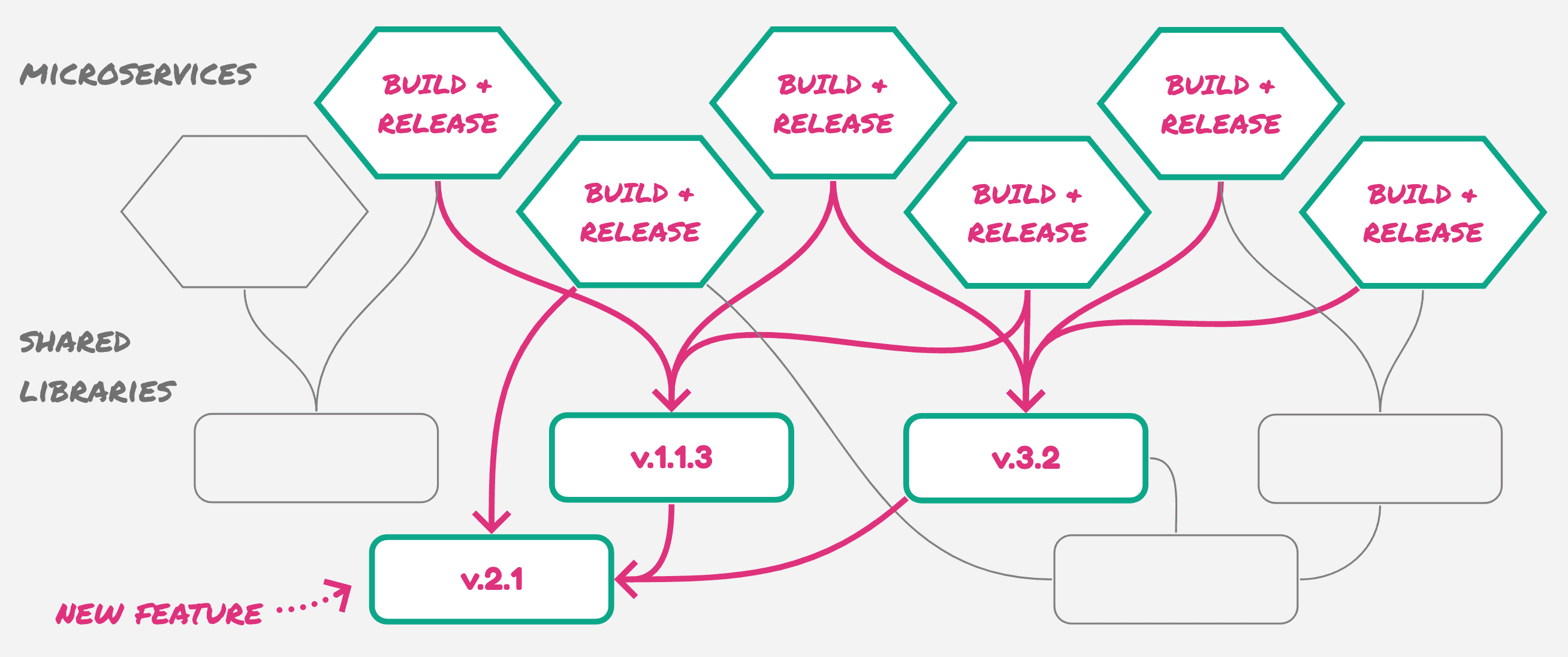
In a fragmented codebase, with several projects to update, the process is not atomic, error-prone, hard to debug, leading to issues that we don’t always spot in the early phase of development.
Reducing the number of libraries in favor of loose coupling would help move out of this scenario, towards a better codebase.
But how to do it in practice, without rewriting most of the code or making feature development problematic?
What would be the best strategy to make big changes on a large, fragmented codebase, if developing a simple feature
already looks so complicated?
At some point, I wanted to turn this discomfort into an opportunity and explore a solution.
Monorepo, here is the deal
So could monorepo reduce the effort of coordinating many build and release tasks, helping feature development and refactoring in our codebase?
If you have been doing a bit of digging around, monorepo has some drawbacks, but it is indeed appealing!
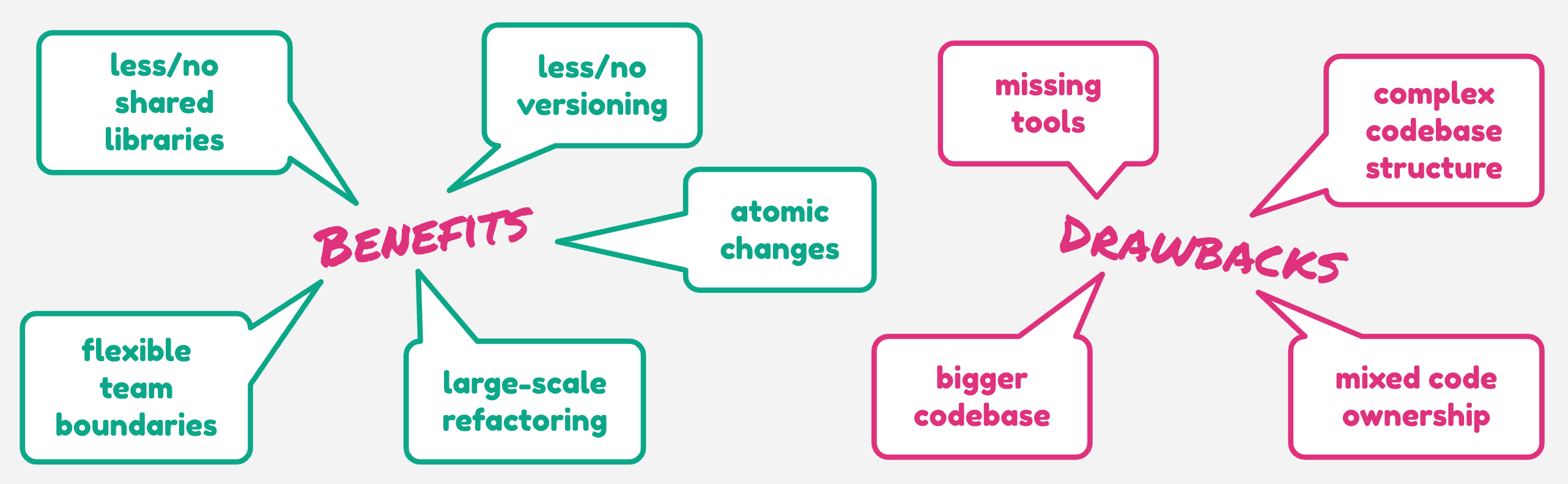
In a monorepo, all source code is in one, organized tree. No need for shared, external libraries. No need to think too much about versioning, releasing, tagging. Any change will reflect onto the entire codebase, and can be verified and applied atomically.
A single source of truth, against the ambiguity of versioning
Perhaps, working with a monorepo, our developers could focus more on the product rather than work on sparse pieces of software.
With multiple teams involved in product development, they could improve cross-team collaboration and share responsibility for governing the development process.
Somewhere in between
Monorepo looks like a big change, and for sure, it won’t come at no cost. Depending on the context, we should evaluate the pros and cons, and avoid negative aspects.
I’m not comfortable with the idea of a monorepo at large scale. An easy guess — involving many teams would be quite complicated, with a high risk of downsides. Yet I’m in favor of breaking the isolation.
Isolation may ensure autonomy but can complicate collaboration
I believe that sharing knowledge and lining up strategies between teams across a bounded context might be an advantage for technology, product, and business together.
Can monorepo help with that?
One, shared codebase where to effectively bring ideas to life.
What about sizing? Perhaps, applying monorepo topology on a reduced codebase, and limiting the scope to a few teams
could be a good trade-off.
Need to find a good balance.
Should I stay or should I go … monorepo?
After all the digging and reading, to satisfy my curiosity I finally decided to invest some time and test how it would work with a monorepo, shared between my team and another.
I decided to start small, setting up a monorepo with a few services, and then try to scale and compare it against the polyrepo strategy.
Key factors for the success of the experiment:
- finding tools to enable the adoption of the monorepo
- must be efficient and scalable, both in local and CI environments
As we’ll see in the next article of the series, “A Monorepo Experiment: reuniting a JVM-based codebase”, my exercise will reveal how monorepo can be productive for JVM-based development.
References
- “Google Monorepo Paper” by Authors Rachel Potvin & Josh Levenberg
- Why Google Stores Billions of Lines of Code in a Single Repository
- Monorepo Explained
- Monorepos: Please don’t! by Matt Klein | Medium
- To Monorepo, Or Not To Monorepo, That Is The Question
- Benefits and challenges of monorepo development practices
- Shared libraries in microservices — avoiding an antipattern
Read next












Written by lastminute.com folks, who live for the holidays. You should follow us on Twitter.

Want to express your love for travel and tech? Well, you could read another article, or you could just come and join us. We’re always looking for talent to help us enrich the lives of travellers - find your role here.
The postings on this site are authors' opinions and experiences and do not necessarily represent the postings, strategies or opinions of lastminute.com group.