
Technology
A Monorepo Experiment: reuniting a JVM-based codebase


Continuing the Monorepo exploration series, we’ll see in action a real-life example of a monorepo for JVM-based languages, implemented with Maven, that runs in continuous integration. The experiment of reuniting a codebase of ~700K lines of code from many projects and shared libraries, into a single repository.
Today I want to tell you in detail about our experience with monorepo for JVM-based applications in
lastminute.com.
Our codebase has been shaped for years with a polyrepo topology, and in some cases it showed high complexity of use.
The monorepo experiment aims to find an alternative.
The experiment consists of migrating the source code from a number of interconnected repositories into a monorepo. The perimeter of the experiment will be my daily working environment. We work on microservices in Java and Kotlin, using Maven, with a feature-based workflow in GitLab.
Some numbers about the codebase:
- 9K+ files, ~700K lines of code (Java & Kotlin)
- 10+ microservices
- 10 developers, in 2 teams that work on connected bounded contexts
An interesting fact: the codebase is the result of migrating away from a monolith architecture.
During the years, the code of the original monolith was sometimes converted into shared libraries,
or sometimes duplicated.
There are still some software projects that need to be split into separate functions
that belong to different bounded contexts.
This should give you a general idea of how connected the projects are
and how coupled the services that build from them.
Together with the usual problems of the migration from a monolith, the pain points of the polyrepo strategy came out.
As presented in the first article of our series, “Exploring the Monorepo”, in theory monorepo offers atomicity, efficiency, and consistency, even in those challenging operations where polyrepo often fails, like large-scale refactoring or upgrading the technology.
It’s time to prove it
Monorepo tools
Among the very few tools that support monorepo, none can do with Maven. Searching around, we found only a couple of experiments with a monorepo that builds with Maven.
Nevertheless, we decided to develop what was needed for our experiment, choosing not to introduce new building tools, and using Maven.
Even though the experiments matched our ideal structure, there were some missing features and qualities, like scalability. With no optimization in place, the whole codebase is rebuilt every time, and so the build time grows with the codebase size.

Monorepo structure
For those who are familiar with Maven, our monorepo structure is a big multimodule Maven project that connects many software modules and libraries.
The structure is intuitive. Under deployments, some configurations define the packaging and delivery of the microservices in continuous integration.
Partial build
Once the structure was defined, we moved on to design a smart process that could keep the build scalable.
The idea, called partial build, is to build only the modules affected by changes, together with all the dependent modules, up to the microservices that contain those modules.
A prerequisite to enabling partial build is to properly configure the multimodule Maven project.
All dependencies between monorepo modules and libraries must be declared by the developers through profiles in the Maven poms.
With these profiles, our smart process will be able to select a set of modules for the build.
We’ll see it in practice.
In a local environment, a developer can manipulate Maven and be in control of what to build and verify. But in CI the partial build must be automatic.
We designed a CI pipeline that integrates GitLab features to detect changes in the source code from the last green pipeline. The pipeline dynamically executes a number of tasks and builds only the microservices that contain changes. Tasks include preparing the Maven environment, building and testing all software modules, running integration / pact / acceptance tests and static analysis, publishing artifacts on Nexus, and eventually delivering microservices in our QA environment.
Monoversion
There are different known strategies to apply versioning to the code in a monorepo. We chose monoversion, where the code that is selected for a build is all tagged together with one version. No inconsistencies.
Possibly in a polyrepo there are many libraries to manage, and multiple services to release. Here, there is no versioning or releasing of libraries in the middle.
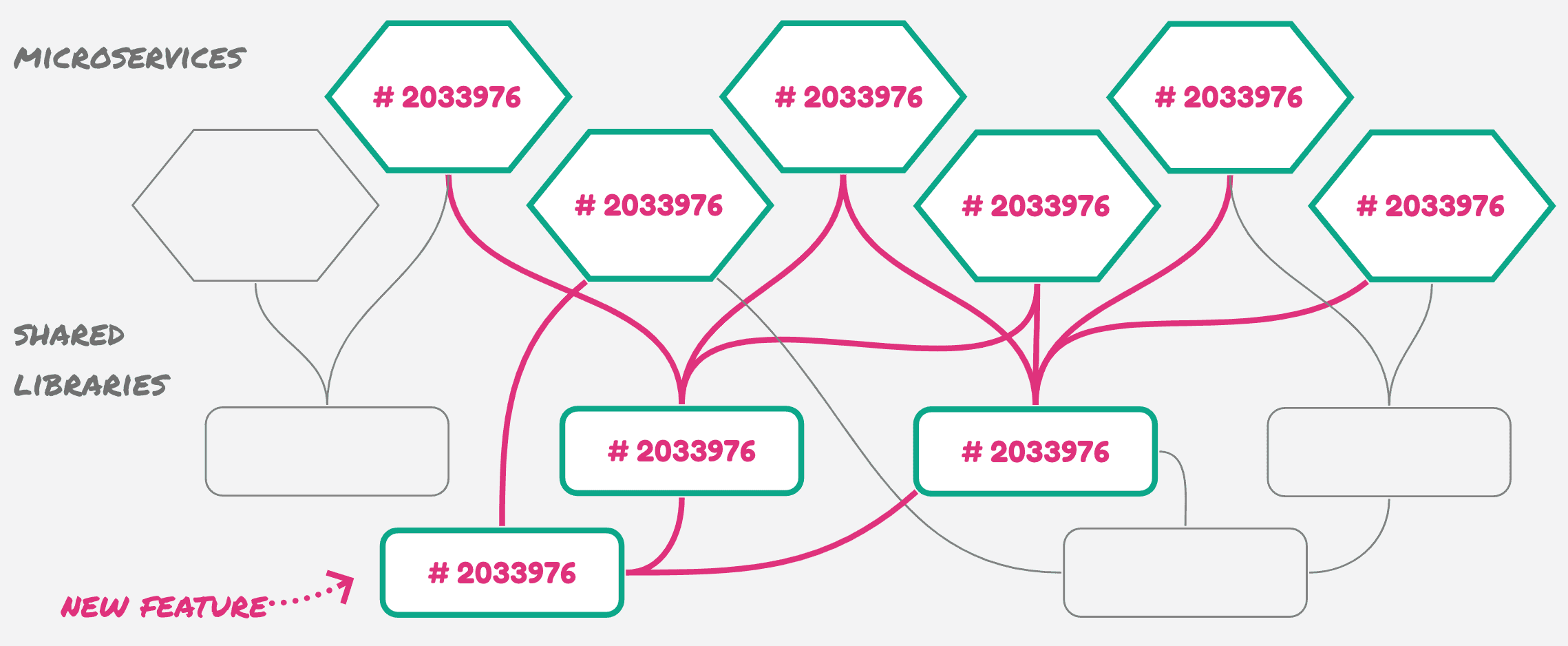
It is an automatic process. When pushing changes into GitLab, the pipeline number is set as the version.
Please note that this is equivalent to what a developer would do manually in a polyrepo topology. We’d expect that the cost of a build in the polyrepo should be comparable to monorepo, but here the difference is that all the code is compiled, verified and delivered at once.
As promised, we are reducing the inconsistencies and getting rid of the complexity of versioning that emerged with the polyrepo.
The overall strategy
We start small and gradually expand. We can test our development process and measure the scalability and performance of the monorepo.
The plan is simple. The devil is in the details.
Step one
First, we migrate the source code from 2 Git repositories, containing the projects sts and search-driver-1. These projects build 3 microservices, sts-search, sts-checkout, and sts-search-driver-1. No shared libs. Starting from the root of the monorepo, we configure the pom files with all modules and dependencies.
Local build process
Launching a Maven build from the root pom in the local environment builds the whole monorepo codebase.

The full build works. Let’s configure the Maven profiles for the partial build.

In our idea, profiles should have the names of the microservices, because in the end this is what a partial build should produce. Now let’s try two partial builds in the local environment, with the profiles sts-search and sts-search-driver-1.

CI partial build
The CI pipeline uses a Python script that analyzes the changes in the source code and selects the monorepo modules and libraries to build.
The script also finds all modules that depend on the modules affected by changes, by simply navigating the very same Maven profiles used by the developer for the local build.
When the CI pipeline is triggered, the script provides a list of modules and profiles, and the pipeline executes only the necessary tasks to produce the microservices that need to be rebuilt.

Pushing the initial changes triggered a full build in CI, which produced all the microservices. Let’s make a small change, e.g. to the search-driver-1 source code, and trigger the partial build.

The minimum set of modules is selected, and the pipeline executes only the necessary tasks to build the sts-search-driver-1 microservice.
One small step for a man …
The partial build works! This smart process can be improved, but it’s performing just fine for our case in CI.
CI times comparison
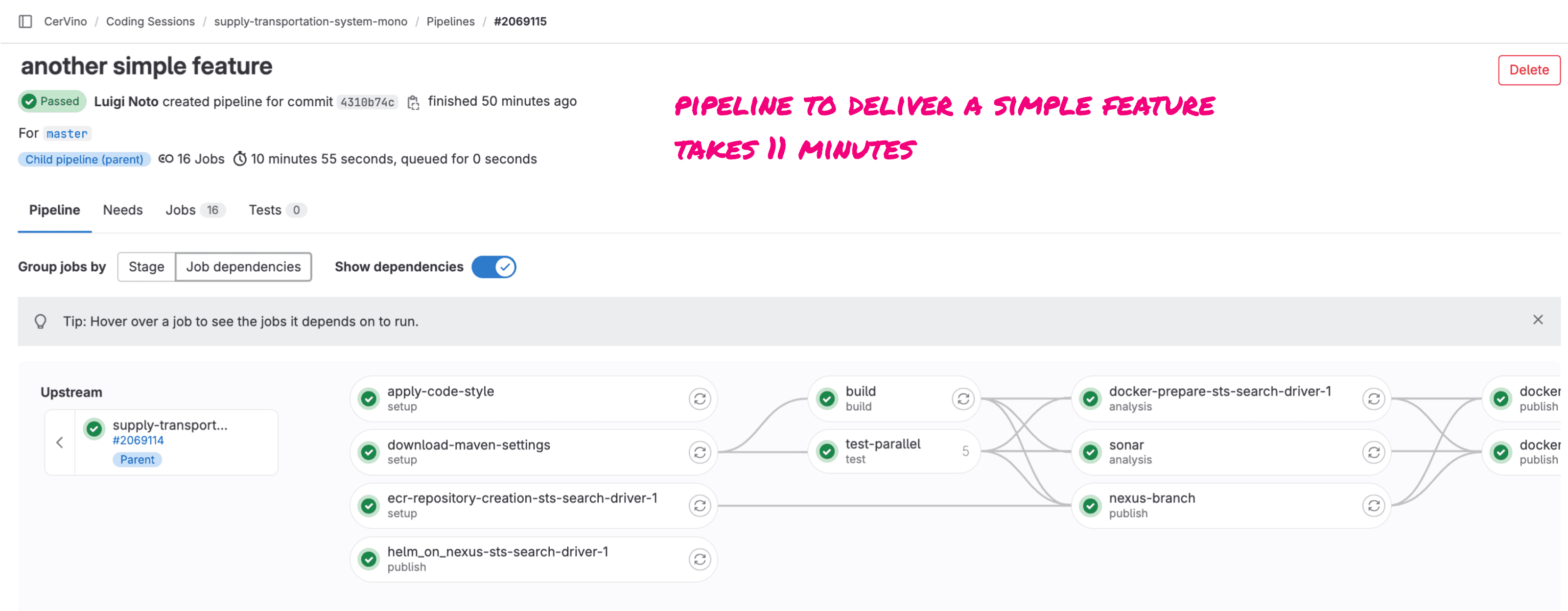
It’s interesting to measure and compare the monorepo against a development process applied to the two original repositories. Assume we have to develop a feature in the core of the sts system. The feature will be integrated into the search-driver-1 microservice. With polyrepo, we have to work in branches of the 2 repositories.
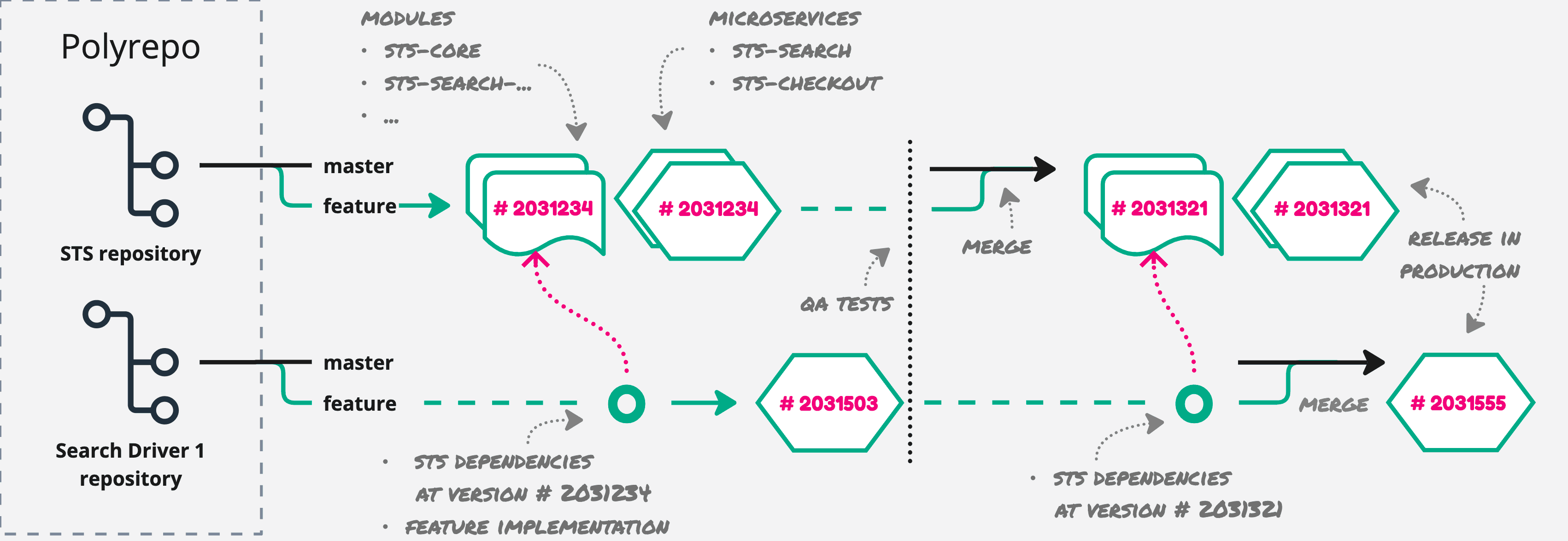
On average, the pipeline of sts takes ~14 minutes, and the search-driver-1’s one is ~5 min. The same feature will be developed in the monorepo with the following process.

The feature will be implemented and verified in the core of the sts module and together in the search-driver-1 module. Working on a branch and merging on master will trigger the partial build in CI, and eventually produce the 3 microservices. In the monorepo, building in CI takes ~16 min.
It’s been proven that build times in monorepo are comparable to or even better than in polyrepo. That is plausible, even just for the fact that more tasks can run in parallel in one big pipeline.
Perhaps two more important qualities of the monorepo can be observed from the test: atomicity and consistency.
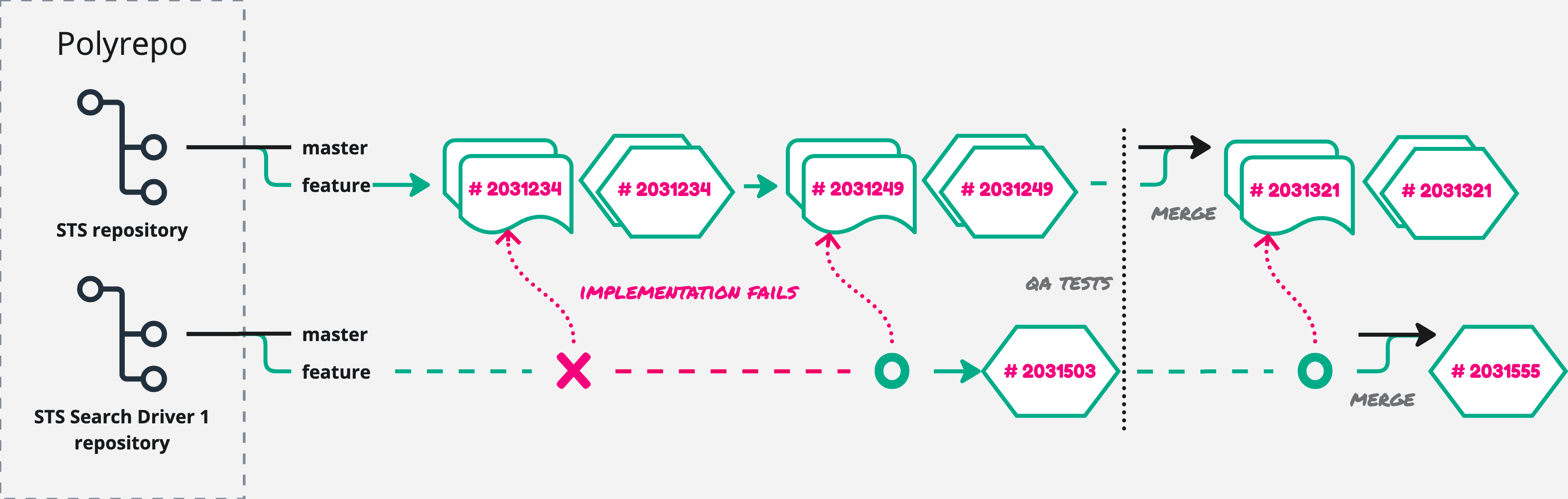
With the polyrepo, after the pipeline of sts, we would import the new version in search-driver-1 to complete the feature. But once there, the implementation might be incompatible or insufficient, forcing us to reiterate the process.
In the monorepo, we can eliminate the weak point by avoiding multiple, isolated development steps. Developing a feature in internal modules and libraries is atomic and consistent and requires less versioning and coordination.
Moreover, by adding microservices, modules, and libraries, presumably the complexity will increase more in polyrepo than monorepo.
Step two – let’s raise the bar
In preparation for step two, we migrated into the monorepo 5 more projects, 2 shared libraries, and a web tool from as many repositories. With ~400K lines of code, we are halfway to reuniting the codebase.
Our goal is to verify the scalability of monorepo, or find the limit due to codebase size. For the build in local, I increased a bit the memory assigned to my IDE – I’m using 1 GB for the build process, 1 GB for the Maven importer, and 4 GB as the maximum heap size.
Now let’s try the process of developing a feature into a shared library that would be integrated into many of the search drivers and the web tool.
With the polyrepo, we would start with the shared library, and then we would import it into sts first, to make a new version of the core modules. With these artifacts ready, we would work on the search drivers, updating their dependencies, developing the feature and running the pipelines. Finally, we could complete the feature in the web tool.
Of course, there are ways to speed up the process in the polyrepo, e.g. work locally, on multiple branches. But still, it is indisputable that scaling up with the codebase size, this process would require more and more versioning and coordination.
Observing the whole process in the polyrepo is not worth it. Instead, let’s measure the monorepo.

As you can expect, process steps remain the same, while pipeline build time increases a bit, due to the high number of resources and jobs that GitLab has to make available and coordinate.
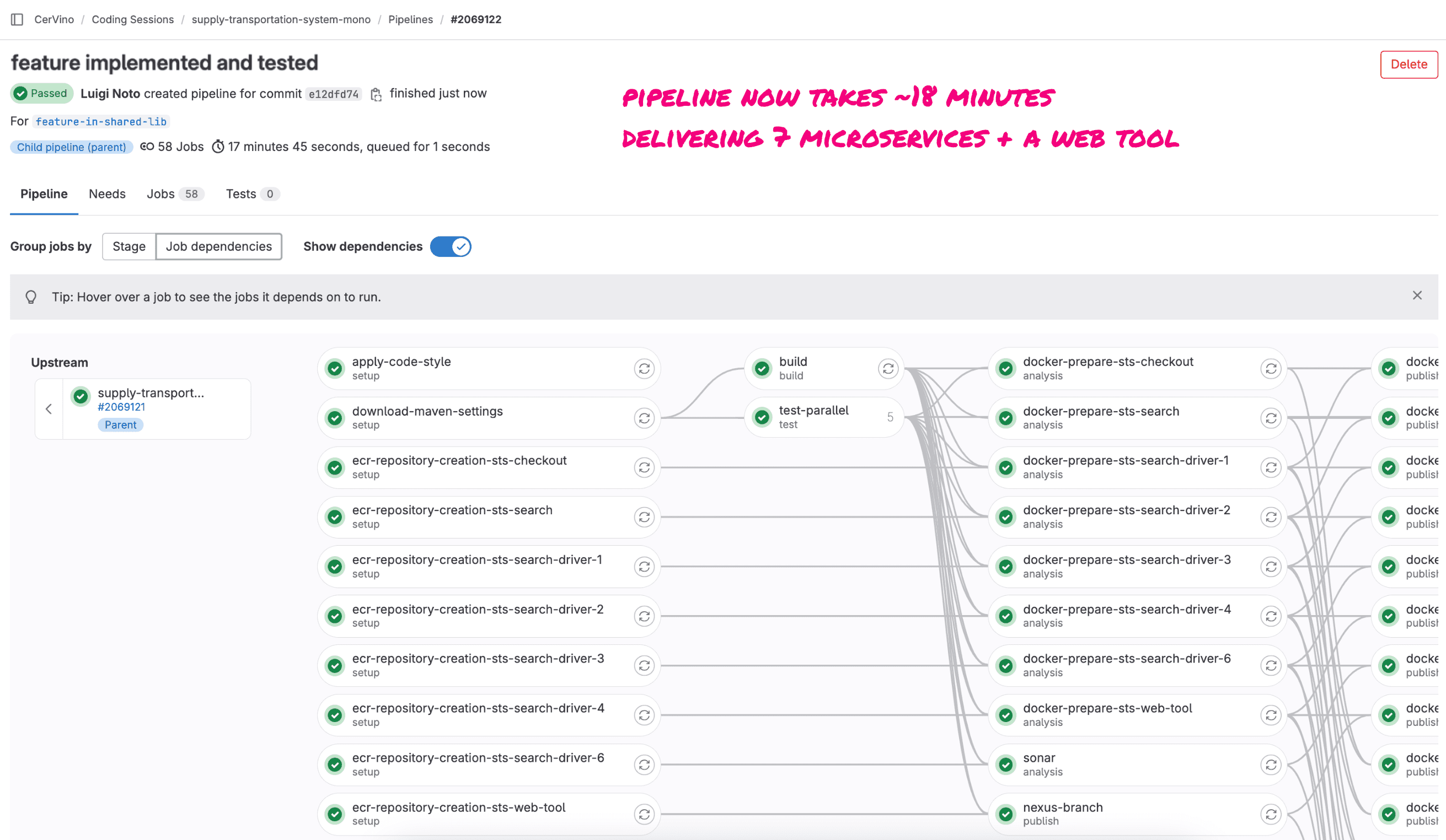
In comparison, a feature that impacts less the codebase will require fewer CI resources and should be quicker.
What’s next
Even after adding a lot of complexities to the monorepo structure, it turns out that the build process both locally and in CI remains scalable.
But what can we say about other common software development operations?
My IDE and Maven locally show no degradation in performance. Given the current size of the codebase, branching the monorepo and other Git operations do not require particular attention.
In the monorepo, features could be developed entirely on a single branch, even the most elaborated ones. Likely, we could go on to master only upon completion of development. So now feature branches live longer than in polyrepo. Should this be considered positive or negative?
We leave the question to the reader.
Setting limits on the growth of the monorepo is also an open point. We’ll keep migrating projects from our codebase into the monorepo, as long as we see advantages.
Another element to consider is codebase ownership. The entire codebase spawns over two bounded contexts. If we end up migrating the whole codebase into the monorepo, the number of developers and features developed in parallel would increase. If we make this choice, is there any strategy to avoid conflicts? GitLab can help — it’s called Codeowners.
I would also like to bring another fact about the codebase to our attention: the majority of the source code for
the search drivers still resides in the sts project. Our plan is to split this code, as it would be a significant
step to undo the monolith. However, this would require substantial refactoring.
Based on what we have seen in our experiment, perhaps the monorepo represents a winning strategy, worth investing
before beginning the refactoring.
And so, many aspects still remain to be explored.
The making of the experiment was a team effort — fun but challenging. It started just out of curiosity and turned into an opportunity to optimize our team processes. For Codeowners, refactoring, and other experiments, stay tuned for the next episodes of the monorepo exploration series.
References
Read next


From Months to Weeks: The Smart Way to Let AI Do a Migration




How we migrated 137 modules to a new dependency-injection pattern with AI, turning a quarter-long slog into a few focused weeks by teaching the AI instead of delegating to it, working in small supervised steps, and letting the method compound. [...]






Written by lastminute.com folks, who live for the holidays. You should follow us on Twitter.

Want to express your love for travel and tech? Well, you could read another article, or you could just come and join us. We’re always looking for talent to help us enrich the lives of travellers - find your role here.
The postings on this site are authors' opinions and experiences and do not necessarily represent the postings, strategies or opinions of lastminute.com group.